
TL;DR:
- DSPy introduces a programming model for LM pipelines, offering a systematic approach.
- Parameterized modules in DSPy learn to apply prompting, fine-tuning, and reasoning techniques.
- A compiler optimizes DSPy pipelines, enhancing quality and cost-effectiveness.
- DSPy’s flexibility is boosted by the use of “teleprompters” for optimal data learning.
- Case studies demonstrate DSPy’s ability to outperform standard prompting by over 25% and 65%.
- DSPy revolutionizes NLP pipeline development with remarkable efficiency.
Main AI News:
Language models (LMs) have revolutionized the field of natural language processing (NLP), enabling researchers to create advanced systems with reduced data requirements. However, a persistent challenge lies in the nuanced art of asking LMs the right questions for each task, especially when multiple LMs are involved in a single process.
The machine learning (ML) community has been actively exploring techniques for prompting LMs and constructing pipelines for complex tasks. Nevertheless, existing LM pipelines often rely on rigid “prompt templates” discovered through trial and error. In their quest for a more systematic approach, a team of researchers, including experts from Stanford, has introduced DSPy. This programming model abstracts LM pipelines into text transformation graphs, akin to imperative computation graphs where LMs are invoked through declarative modules.
The hallmark of DSPy lies in its parameterized modules, capable of learning how to apply combinations of prompting, fine-tuning, augmentation, and reasoning techniques through demonstrations. To optimize any DSPy pipeline, a dedicated compiler has been developed, driven by the aim of enhancing quality and cost-effectiveness. This compiler takes the program itself, along with a small set of training inputs, into account, potentially including optional labels and a validation metric for performance evaluation. Its operation involves simulating diverse program versions using these inputs, generating example traces for each module. These traces serve as a foundation for self-improvement, facilitating the creation of effective few-shot prompts and the fine-tuning of smaller language models at various pipeline stages.
Notably, DSPy’s optimization approach is remarkably flexible, leveraging “teleprompters” as versatile tools to ensure that every component learns optimally from the available data.
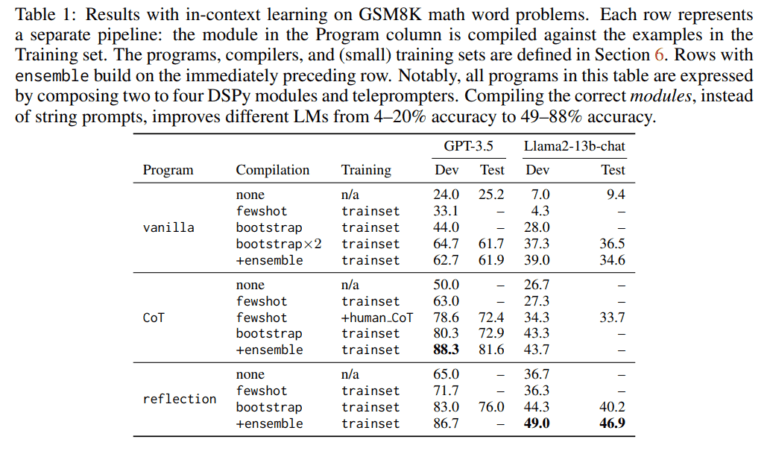
Through two illuminating case studies, DSPy has proven its ability to express and optimize concise LM pipelines, proficient in solving mathematical word problems, handling multi-hop retrieval, addressing complex queries, and controlling agent loops. Impressively, mere minutes after compilation, a few lines of DSPy code empower GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting by extraordinary margins, exceeding 25% and 65%, respectively.
Conclusion:
This work presents a groundbreaking approach to natural language processing, embodied by the DSPy programming model and its associated compiler. By translating intricate prompting techniques into parameterized declarative modules and harnessing the power of general optimization strategies (teleprompters), this research introduces a revolutionary way to construct and optimize NLP pipelines with unparalleled efficiency.