
TL;DR:
- EAGLE, a novel machine learning method, addresses the efficiency challenges in Large Language Model (LLM) decoding.
- It diverges from traditional methods, focusing on second-top-layer feature vectors extrapolation.
- EAGLE utilizes the FeatExtrapolator plugin, achieving remarkable speed increases in text generation.
- Its performance metrics include a threefold speed boost over vanilla decoding and outperforming Medusa and Lookahead.
- EAGLE maintains text distribution consistency while being accessible for standard GPUs.
- The FeatExtrapolator collaboration with the Original LLM’s embedding layer is pivotal.
- EAGLE redefines LLM decoding, offering efficiency and quality preservation.
Main AI News:
In the realm of natural language processing, Large Language Models (LLMs) have undeniably transformed the landscape, showcasing their prowess in various language-related tasks. However, these remarkable models have grappled with a formidable challenge – the auto-regressive decoding process, a method where each token necessitates a full forward pass. This computational bottleneck is especially pronounced in LLMs boasting expansive parameter sets, leading to constraints in real-time applications and posing significant challenges for users with limited GPU capabilities.
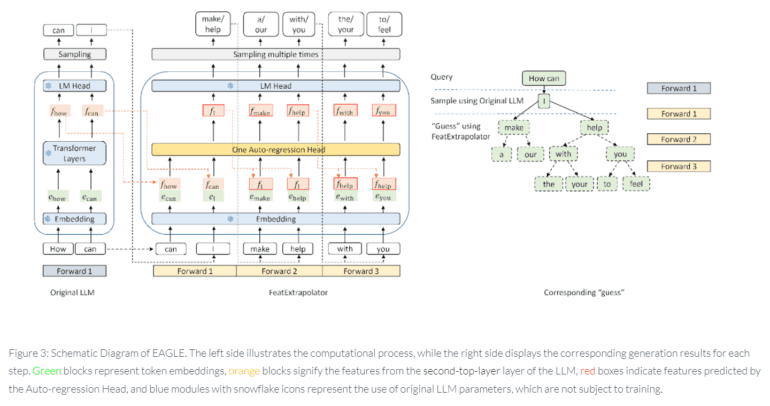
Enter EAGLE (Extrapolation Algorithm for Greater Language-Model Efficiency), a groundbreaking solution introduced by a collaborative team of researchers from Vector Institute, the University of Waterloo, and Peking University. Diverging from conventional decoding methods exemplified by Medusa and Lookahead, EAGLE charts its own course by honing in on the extrapolation of second-top-layer contextual feature vectors. What sets EAGLE apart is its commitment to predicting subsequent feature vectors with unprecedented efficiency, offering a breakthrough that propels text generation to new heights.
At the heart of EAGLE’s innovative methodology lies the deployment of a lightweight yet powerful plugin known as the FeatExtrapolator. Trained in conjunction with the Original LLM’s frozen embedding layer, this plugin excels in predicting the next feature based on the current feature sequence from the second top layer. EAGLE’s theoretical foundation rests on the compressibility of feature vectors over time, paving the way for an expedited token generation process. What truly distinguishes EAGLE is its outstanding performance metrics – it boasts a threefold speed increase compared to vanilla decoding, doubles the speed of Lookahead, and achieves a 1.6 times acceleration compared to Medusa. Perhaps most crucially, it maintains consistency with vanilla decoding, ensuring the preservation of the generated text distribution.
But EAGLE’s impact goes beyond acceleration. It democratizes access by being compatible with standard GPUs, making it accessible to a broader user base. Its seamless integration with various parallel techniques adds versatility to its application, further solidifying its position as an invaluable addition to the toolkit for efficient language model decoding.
One cannot overlook the pivotal role played by the FeatExtrapolator in EAGLE’s success. This lightweight yet potent tool collaborates seamlessly with the Original LLM’s frozen embedding layer, predicting the next feature based on the second top layer’s current feature sequence. EAGLE’s theoretical foundation, rooted in the compressibility of feature vectors over time, streamlines the token generation process like never before.
While traditional decoding methods demand a full forward pass for each token, EAGLE’s feature-level extrapolation opens up a novel avenue for surmounting this challenge. The research team’s theoretical exploration culminates in a method that not only significantly accelerates text generation but also upholds the integrity of the distribution of generated texts – a critical aspect for maintaining the quality and coherence of the language model’s output. EAGLE is a game-changer in LLM decoding, setting a new standard for efficiency in the world of natural language processing.
Conclusion:
EAGLE’s introduction marks a significant leap in the efficiency of LLM decoding. Its innovative approach, outstanding performance, and compatibility with standard GPUs position it as a game-changer in the natural language processing market. Researchers, developers, and businesses can benefit from faster and more accessible language model decoding, opening up new possibilities for real-time applications and user experiences.