
- Large language models (LLMs) demand substantial memory and bandwidth due to their extensive parameter sizes.
- Existing quantization methods, such as post-training quantization (PTQ) and quantized parameter-efficient fine-tuning (Q-PEFT), often require significant training resources and can impact accuracy.
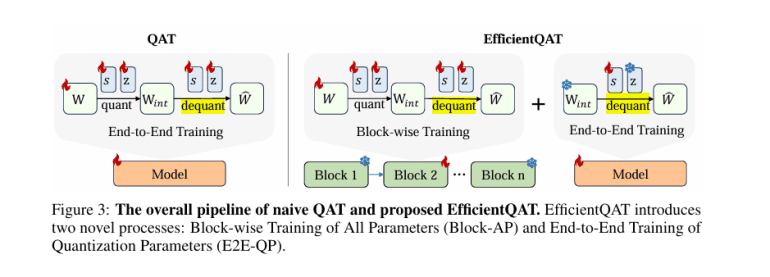
- Efficient Quantization-Aware Training (EfficientQAT) introduces a two-phase approach to address these challenges.
- The Block-AP phase involves quantization-aware training of all parameters within transformer blocks, using block-wise reconstruction to save memory.
- The E2E-QP phase trains only the quantization parameters while keeping the quantized weights fixed, enhancing model efficiency and performance.
- EfficientQAT enables a 2-bit quantization of the Llama-2-70B model on a single A100-80GB GPU in 41 hours with minimal accuracy loss.
- This method outperforms existing Q-PEFT techniques in low-bit scenarios, offering improved hardware efficiency.
Main AI News:
In the realm of artificial intelligence, large language models (LLMs) are becoming increasingly crucial, yet their extensive parameter sizes result in substantial memory and bandwidth demands. While quantization-aware training (QAT) presents a potential solution by enabling models to operate with lower-bit representations, existing methods often necessitate considerable training resources, rendering them impractical for large models. This research paper introduces Efficient Quantization-Aware Training (EfficientQAT), a novel approach designed to tackle the memory challenges associated with LLMs in natural language processing and AI.
Current quantization strategies for LLMs include post-training quantization (PTQ) and quantized parameter-efficient fine-tuning (Q-PEFT). PTQ reduces memory consumption during inference by converting pre-trained model weights to low-bit formats, but this can lead to accuracy loss, particularly in low-bit regimes. Q-PEFT methods, such as QLoRA, allow fine-tuning on consumer-grade GPUs but require reversion to higher-bit formats for additional tuning, necessitating another round of PTQ, which can affect performance.
EfficientQAT offers a solution by introducing a two-phase approach. The first phase, Block-AP, involves quantization-aware training of all parameters within each transformer block, employing block-wise reconstruction to enhance efficiency. This method circumvents the need for full model training, conserving memory resources. In the second phase, E2E-QP, the quantized weights are fixed, and only the quantization parameters (step sizes) are trained, boosting the model’s efficiency and performance without the overhead of training the entire model. This dual-phase method improves convergence speed and allows effective instruction tuning of quantized models.
Block-AP begins with a standard uniform quantization technique, applying quantization and dequantization to weights in a block-wise manner. Drawing inspiration from BRECQ and OmniQuant, this approach enables efficient training with reduced data and memory compared to traditional end-to-end QAT methods. By training all parameters, including scaling factors and zero points, Block-AP ensures precise calibration while avoiding the overfitting issues commonly encountered with full model training.
The E2E-QP phase focuses on training only the quantization parameters end-to-end, keeping the quantized weights fixed. Leveraging the robust initialization from Block-AP, this phase allows efficient and accurate tuning of the quantized model for specific tasks. E2E-QP facilitates instruction tuning of quantized models, ensuring memory efficiency as only a small fraction of the total network is trainable.
EfficientQAT demonstrates substantial advancements over previous quantization techniques. For example, it achieves a 2-bit quantization of a Llama-2-70B model on a single A100-80GB GPU in just 41 hours, with less than 3% accuracy degradation compared to the full-precision model. Moreover, it surpasses existing Q-PEFT methods in low-bit scenarios, offering a more hardware-efficient solution.
Conclusion:
Efficient Quantization-Aware Training (EfficientQAT) presents a major advancement in the field of model quantization, addressing key limitations of current techniques by significantly reducing memory and computational demands. By optimizing quantization through a dual-phase approach, EfficientQAT not only improves efficiency and performance but also makes large language models more practical for deployment in resource-constrained environments. This innovation is likely to influence the market by setting new standards for model compression and efficiency, potentially driving broader adoption of LLMs in various AI applications.