
- Research unveils groundbreaking approach to large language models (LLMs) by eliminating matrix multiplication (MatMul).
- MatMul-free architectures demonstrate performance on par with state-of-the-art Transformers, even up to 2.7 billion parameters.
- Innovative strategies reduce memory usage during training by 61% and memory consumption during inference by a factor of ten.
- Hardware solution leveraging FPGAs enables billion-parameter scale models to operate at just 13 watts, nearing human brain efficiency.
Main AI News:
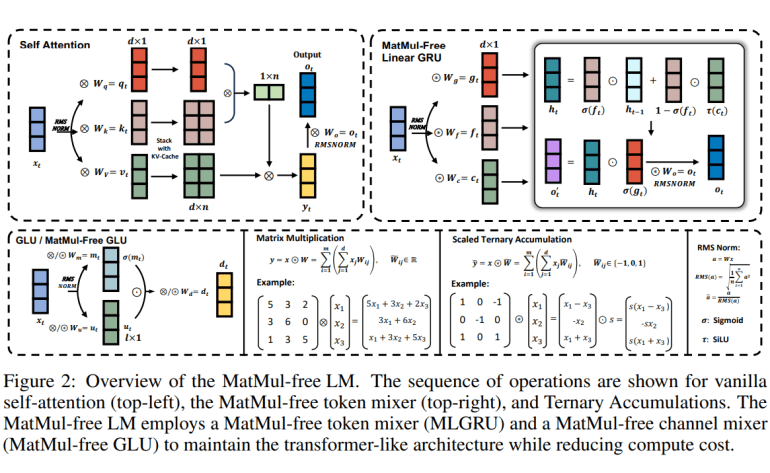
As the demand for powerful neural network architectures continues to surge, the reliance on matrix multiplication (MatMul) remains a cornerstone in their design. Whether it’s the vector-matrix multiplication (VMM) prevalent in dense layers or the matrix-matrix multiplication (MMM) central to self-attention mechanisms, MatMul operations are integral, optimized primarily for GPU performance. However, recent breakthrough research challenges this paradigm, suggesting that large language models (LLMs) can achieve remarkable efficiency gains by eliminating MatMul altogether.
A collaborative effort led by researchers from the University of California, Santa Cruz, Soochow University, University of California, Davis, and LuxiTech unveils a groundbreaking approach. Their study reveals that for models up to 2.7 billion parameters, MatMul-free architectures exhibit performance levels on par with state-of-the-art Transformers, renowned for their computational intensity. This revelation underscores a fundamental shift, indicating that as LLMs scale, reliance on MatMul diminishes without compromising efficacy.
Moreover, the team introduces innovative strategies to streamline implementation and optimize performance. By leveraging GPU-efficient techniques, they achieve a staggering 61% reduction in memory usage during training, addressing critical practical concerns. Furthermore, an optimized inference kernel slashes memory consumption by a factor of ten, enhancing accessibility and efficiency across diverse applications.
Not stopping at software enhancements, the team pioneers a hardware solution leveraging Field-Programmable Gate Arrays (FPGAs). This pioneering technology enables billion-parameter scale models to operate at a mere 13 watts, capitalizing on lightweight operations beyond conventional GPU capabilities. The result? LLMs edging closer to the energy efficiency of the human brain, ushering in a new era of computational prowess.
This transformative research underscores the viability of MatMul-free approaches in simplifying LLM complexity while maintaining peak performance. Furthermore, it delineates a roadmap for future hardware accelerators, emphasizing the importance of lightweight operations in processing next-generation LLMs. With these advancements, large language models emerge as more effective, scalable, and practical tools, poised to revolutionize various domains.
Conclusion:
This research marks a significant milestone in the evolution of large language models, demonstrating that MatMul-free approaches can simplify complexity without sacrificing performance. Businesses across various sectors can leverage these advancements to develop more efficient and scalable language processing solutions, unlocking new possibilities for innovation and market disruption.