
TL;DR:
- SAM, a powerful image segmentation model, has transformed computer vision.
- Meta AI introduces EfficientSAM, a cost-effective solution with superior performance.
- SAMI technology offers pre-trained lightweight ViT backbones for various tasks.
- EfficientSAM models excel in object detection, instance segmentation, and semantic segmentation.
- Meta AI’s strategy outperforms competitors, even for smaller models.
- EfficientSAM outshines competitors in zero-shot instance segmentation.
Main AI News:
In the realm of computer vision, Meta AI’s Segment Anything Model (SAM) has emerged as a true game-changer. It has notched up impressive achievements in a wide array of image segmentation tasks, including groundbreaking feats such as zero-shot object proposal generation, zero-shot instance segmentation, and precise edge detection. With practical applications spanning various domains, SAM has become the go-to foundation model for vision-based AI endeavors.
At the heart of SAM’s remarkable performance lies the SA-1B visual dataset, a colossal repository housing over a billion meticulously crafted masks derived from a staggering eleven million images. This dataset forms the bedrock upon which SAM’s Vision Transformer (ViT) model is built. This robust foundation empowers SAM with the extraordinary capability to segment virtually any object or entity within an image. It’s important to note that SAM’s prowess transcends the boundaries of vision alone.
However, there’s one significant hurdle that hampers the widespread adoption of the SAM model—its cost, particularly the computational expense associated with the image encoder, notably the ViT-H variant. In the pursuit of efficiency, various research publications have surfaced, offering innovative solutions that alleviate the financial burden associated with leveraging SAM for prompt-based instance segmentation.
One such approach suggests harnessing the capabilities of a leaner ViT image encoder, drawing from the expertise of the default ViT-H picture encoder. Real-time CNN-based designs are another avenue explored to trim the computational overhead tied to Segment Anything’s activities. Another proposal advocates for the use of a well-trained lightweight ViT image encoder, exemplified by ViT-Tiny or ViT-Small, as a means to streamline SAM without compromising its formidable performance.
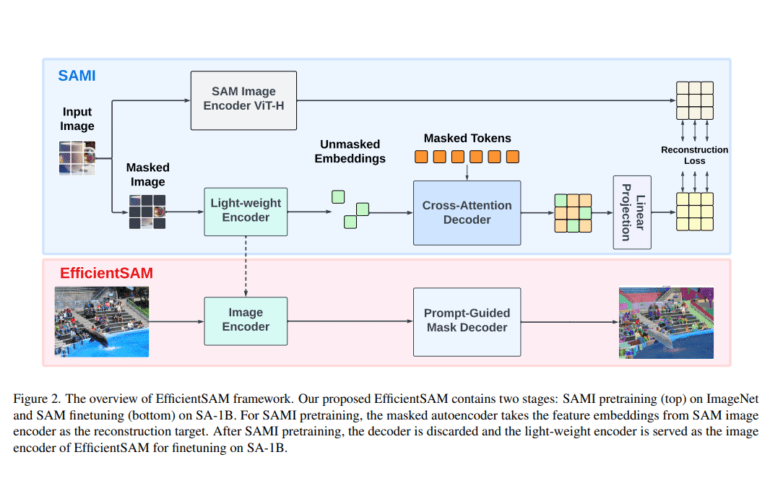
In a groundbreaking move, Meta AI’s research team has pioneered the development of pre-trained lightweight ViT backbones tailored to meet the requirements of various tasks, all thanks to their innovative SAM-leveraged masked image pertaining (SAMI) technology. This involved creating high-quality pre-trained ViT encoders using the renowned MAE pretraining method, synergizing seamlessly with the SAM model.
To delve deeper into SAMI’s mechanics, this approach involves training a masked image model using lightweight encoders, enabling it to reconstruct features extracted from ViT-H within the SAM architecture. Furthermore, it employs the SAM encoder, ViT-H, to provide essential feature embeddings. The outcome? A set of versatile ViT backbones that can be seamlessly integrated into subsequent operations, spanning picture categorization, object identification, and sophisticated segmentation tasks. Subsequently, these pre-trained lightweight encoders undergo fine-tuning to cater specifically to segment-related tasks, achieving remarkable results.
Not stopping there, Meta AI’s dedicated teams introduce EfficientSAMs—streamlined SAM models meticulously crafted to strike a perfect balance between quality and efficiency, ideal for real-world implementation. The models undergo a rigorous pretraining process on ImageNet, leveraging a reconstructive loss function with a 224×224 image resolution. Subsequently, fine-tuning occurs on target tasks using supervised data to evaluate their effectiveness in a transfer learning context for masked image pretraining.
The results speak for themselves. SAMI-driven models exhibit outstanding generalizability, with models trained on ImageNet-1K surpassing the competition, including ViT-Tiny, ViT-Small, and ViT-Base. A ViT-Small model, for instance, attains a remarkable 82.7% top-1 accuracy when fine-tuned on ImageNet-1K with 100 epochs, outperforming other state-of-the-art image pretraining benchmarks. Moreover, Meta AI’s expertise extends to areas such as object detection, instance segmentation, and semantic segmentation, where their pretrained models undergo further refinement.
In a head-to-head comparison with existing pretraining benchmarks, Meta AI’s strategy consistently emerges as the superior choice, even for smaller models, showcasing substantial improvements. To validate their progress, the Segment Anything challenge serves as a litmus test. The results are unequivocal—Meta AI’s model outshines competitors like FastSAM and current lightweight SAM algorithms, delivering an impressive 4.1AP/5.2AP improvement on COCO/LVIS in zero-shot instance segmentation.
Conclusion:
Meta AI’s EfficientSAM technology signifies a monumental leap forward in the world of AI vision. With its innovative approach, it not only significantly reduces computational costs but also sets new benchmarks for performance and efficiency. The era of highly efficient AI vision has arrived, and EfficientSAM leads the charge.