
TL;DR:
- Large language models (LLMs) face challenges, including prompt brittleness and biases.
- Calibration methods are crucial to mitigate these issues and enhance LLM performance.
- Google AI introduces Batch Calibration (BC), a zero-shot method for addressing contextual bias.
- BC outperforms previous calibration methods in zero-shot and few-shot learning scenarios.
- BC’s simplicity and adaptability make it a practical solution for prompt brittleness and bias in LLMs.
- BC’s effectiveness promises enhanced performance in natural language understanding and image classification.
Main AI News:
Large language models (LLMs) have been a game-changer in the realms of natural language understanding and image classification. However, they come with their own set of challenges, most notably, prompt brittleness and the presence of multiple biases within the input. These biases can arise from factors such as formatting, the selection of verbalizers, and the specific examples used for in-context learning. Addressing these issues is crucial to ensure consistent and reliable performance.
The efforts to combat these challenges have led to the development of calibration methods aimed at mitigating biases and restoring LLM performance. These methods have been on a quest to provide a holistic perspective while also addressing the subtle nuances of the problem. It’s worth noting that LLMs are highly sensitive to the way they are prompted and the choice of templates, verbalizers, as well as the sequencing and content of in-context learning examples can all influence their predictions.
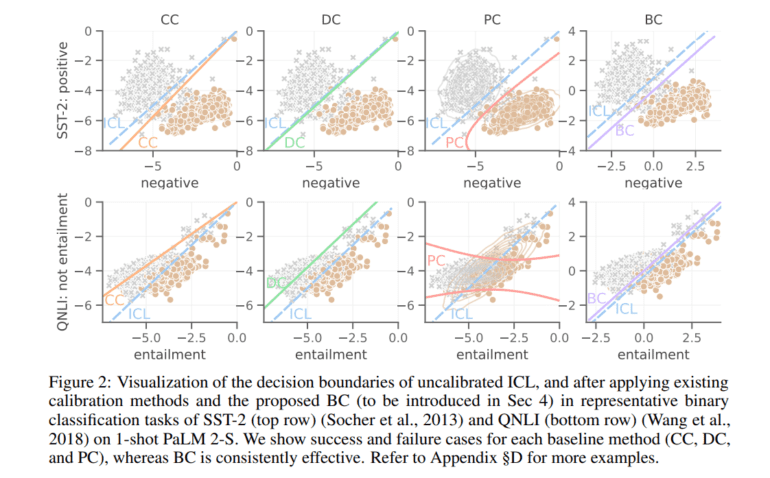
In a significant breakthrough, Google’s research team has introduced a novel approach known as Batch Calibration (BC). BC is a remarkably straightforward yet highly intuitive method designed to target explicit contextual bias within batched inputs. What sets BC apart from other calibration methods is its zero-shot nature and its application exclusively during the inference phase, resulting in minimal additional computational overhead. Furthermore, BC can be extended to a few-shot setup, enabling it to adapt and acquire contextual bias insights from labeled data.
The effectiveness of BC has been rigorously tested across over ten diverse natural language understanding and image classification tasks. In both zero-shot and few-shot learning scenarios, BC has consistently outperformed previous calibration baselines. Its elegant simplicity in design, combined with its ability to learn from limited labeled data, positions BC as a practical and effective solution for addressing prompt brittleness and bias in LLMs.
The metrics obtained from these comprehensive experiments unequivocally demonstrate that BC offers state-of-the-art performance. This makes it a highly promising solution for professionals working with LLMs. By mitigating bias and enhancing robustness, BC streamlines the process of prompt engineering, enabling more efficient and dependable performance from these potent language models.
Conclusion:
The challenges posed by prompt brittleness and biases in large language models find a powerful and innovative solution in Batch Calibration (BC). These methods provide a unified framework for mitigating contextual bias and elevating LLM performance. As natural language understanding and image classification continue to evolve, BC and similar solutions will undoubtedly play a pivotal role in unlocking the full potential of LLMs while minimizing the impact of biases and brittleness in their responses.