
TL;DR:
- Large language models (LLMs) excel in various complex tasks but have limitations.
- PIT framework enables LLMs to self-improve response quality without explicit rubrics.
- PIT closes the quality gap between model-generated and reference responses.
- PIT outperforms prompt-based methods, including Self-Refine.
- Temperature settings impact self-improvement effectiveness.
- Considerations include curriculum reinforcement learning and iteration control.
Main AI News:
In the realm of cutting-edge large language models (LLMs), their exceptional performance in intricate tasks like mathematical reasoning, summarization, conversational prowess, schema induction, and domain-specific problem-solving cannot be denied. The key to their success lies in their ability to comprehend instructions and align seamlessly with human preferences. However, it’s imperative to acknowledge that LLMs are not infallible; they can occasionally produce erroneous information, reasoning blunders, or content that lacks utility.
Efforts have been made to bolster the performance of LLMs, with a burgeoning emphasis on enabling these models to enhance their response quality autonomously. Traditionally, this involved the arduous task of amassing a diverse and high-quality training dataset through human annotation—a resource-intensive endeavor, particularly for specialized domains. In recent times, prompt-based methodologies have garnered acclaim for their efficacy, efficiency, and user-friendliness. Yet, these methods often demand detailed rubrics as inputs, a process that can prove to be both challenging and costly, particularly when striving to achieve complex improvement objectives.
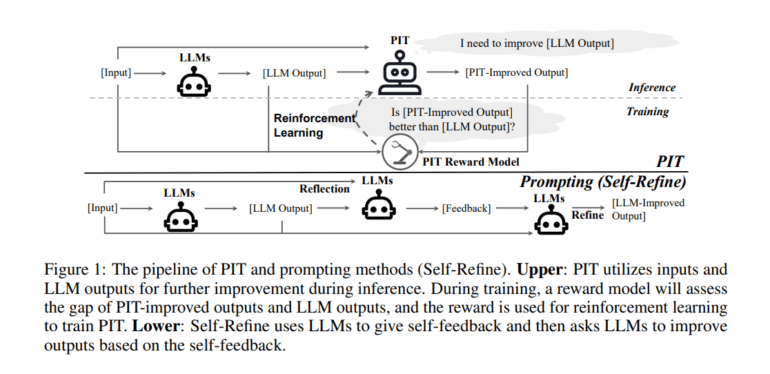
Addressing this pertinent issue, a collaborative effort between researchers from the University of Illinois Urbana-Champaign and Google has given rise to the “Implicit Self-Improvement (PIT) framework.” PIT offers LLMs a unique opportunity to learn the art of self-improvement by discerning improvement goals from human preference data without the need for explicit rubrics. The crux of PIT’s innovation lies in its ability to reshape the training objective of reinforcement learning from human feedback (RLHF). Instead of merely striving to maximize response quality for a given input, PIT aims higher—to optimize the quality gap between the response it generates and a reference response, thus bringing it into closer alignment with human preferences.
To evaluate the prowess of PIT, extensive experiments were conducted on both real-world and synthetic datasets, pitting it against conventional prompt-based methods. The results were nothing short of astonishing, as PIT emerged as the clear frontrunner in the quest to enhance response quality.
PIT’s innovative approach hinges on its ability to relentlessly close the quality gap between model-generated responses and reference responses. This iterative process empowers PIT to improve responses continually, all without the need for explicit rubrics. The real-world and synthetic data experiments serve as compelling evidence of PIT’s superiority over prompt-based methods, reinforcing its effectiveness in elevating LLM response quality.
Notably, PIT doesn’t just outperform its counterparts; it surpasses the Self-Refine method, a technique reliant on prompts for self-improvement. The degree of improvement vis-à-vis Self-Refine may vary depending on the evaluation method—whether it’s human assessment, third-party language models, or reward models. However, one thing remains consistent: PIT consistently reigns supreme in these experiments.
The study also delves into the impact of temperature settings on self-improvement methods, shedding light on the fact that lower temperatures yield superior results when implementing PIT, while higher temperatures are more suitable for Self-Refine. Furthermore, the research underscores the significance of curriculum reinforcement learning and the number of improvement iterations, underscoring the need for careful consideration of stop conditions in practical applications.
Conclusion:
The introduction of the PIT framework represents a significant advancement in the field of large language models. By enabling LLMs to autonomously improve their response quality without the need for explicit rubrics, PIT not only outperforms traditional prompt-based methods but also underscores the importance of temperature settings, curriculum reinforcement learning, and iteration control. This innovation has the potential to reshape the market for LLM-powered applications, offering businesses improved quality in automated interactions and content generation.