
- Large Language Models (LLMs) face operational challenges due to high computational costs during inference.
- CATS (Contextually Aware Thresholding for Sparsity) introduces a novel framework for inducing activation sparsity in LLMs.
- CATS strategically applies non-linear activation functions based on contextual cues to maintain accuracy while reducing computational overhead.
- The framework employs a two-step methodology, identifying neuron relevance and optimizing sparse activations during inference.
- CATS achieves impressive results, maintaining performance within a small margin of full-activation baselines while reducing wall-clock inference times by approximately 15%.
Main AI News:
In today’s dynamic business environment, the demand for streamlined AI solutions continues to grow, with Large Language Models (LLMs) playing a pivotal role in various applications. However, the operational costs associated with these models pose a significant hurdle, particularly during inference phases where computational resources are stretched thin. While existing techniques like quantization and pruning have been explored, the quest for an optimal solution persists.
Introducing CATS (Contextually Aware Thresholding for Sparsity), a cutting-edge framework developed collaboratively by researchers from leading institutions. Departing from traditional methods, CATS employs sophisticated non-linear activation functions that dynamically adjust neuron activation based on contextual cues, striking a delicate balance between activation sparsity and model accuracy.
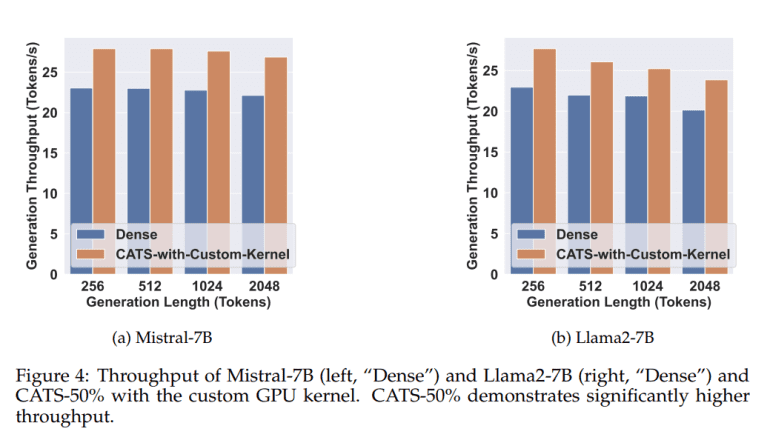
CATS follows a meticulously designed two-step approach, initially identifying neuron relevance through context-sensitive thresholds, validated across popular LLMs and datasets. Subsequently, CATS leverages custom GPU kernels to optimize sparse activations during model inference, harnessing the synergy between software and hardware for maximal efficiency.
The adoption of CATS yields tangible enhancements in computational efficiency and model performance. Rigorous testing on prominent LLMs demonstrates CATS’ ability to maintain performance within a negligible margin of the full-activation baseline while achieving significant activation sparsity. Notably, CATS reduces wall-clock inference times by approximately 15%, underscoring its efficacy in reconciling sparsity and performance.
CATS emerges as a pivotal solution for organizations seeking to deploy large language models without incurring prohibitive operational costs. Its innovative approach, validated through rigorous testing and impressive results, positions CATS as a cornerstone in the quest for enhanced machine learning efficiency, poised to redefine the paradigm of AI deployment in the business landscape.
Conclusion:
The introduction of the CATS framework represents a significant advancement in addressing the operational challenges associated with deploying Large Language Models (LLMs). By effectively balancing activation sparsity and model accuracy, CATS promises to revolutionize machine learning efficiency, offering organizations a viable solution to mitigate computational costs without sacrificing performance. This innovation is poised to reshape the landscape of AI deployment, opening new avenues for enhanced efficiency and productivity in various industries.