
TL;DR:
- VLP, or Video Language Planning, is a groundbreaking AI approach that combines vision-language models with text-to-video dynamics.
- It addresses the challenge of planning for robotic systems by bridging the gap between high-level task descriptions and practical execution.
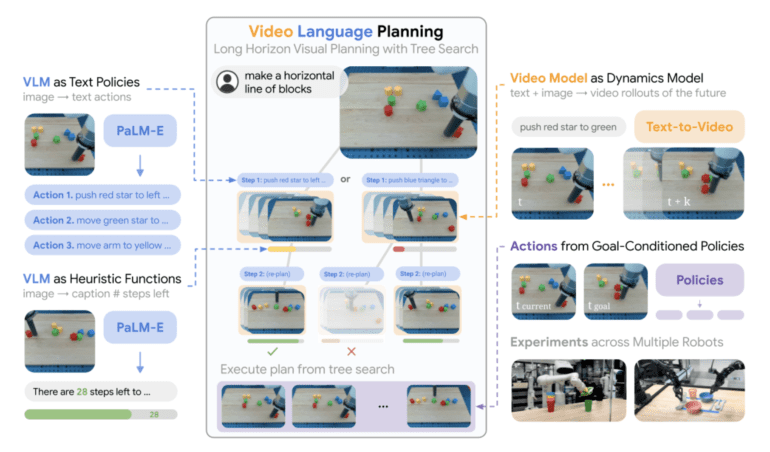
- VLP’s tree search process comprises Vision-Language Models and Models for Text-to-Video, enabling comprehensive task planning.
- It excels in visual planning for complex, long-horizon activities, from object rearrangements to intricate robotic operations.
- The integration of VLP has led to significant improvements in success rates for long-horizon tasks, both in real and simulated environments.
Main AI News:
In the ever-evolving landscape of Artificial Intelligence, generative models are surging ahead at an unprecedented pace. The concept of intelligent interaction with the physical world has taken center stage, emphasizing the critical importance of planning on multiple levels: from the intricate low-level dynamics to the overarching high-level semantic abstractions. These dual layers are paramount for enabling robotic systems to efficiently execute tasks in the real world.
The division of the planning problem into these two layers has long been a fundamental concept in the field of robotics. Consequently, numerous strategies have emerged, combining motion with task planning and formulating control principles for complex manipulation tasks. These strategies aim to formulate plans that account for both the objectives of the task and the dynamic aspects of the physical environment. However, when it comes to Language Learning Models (LLMs), they excel in generating high-level plans based on symbolic task descriptions but struggle with their practical implementation. They often stumble when confronted with tangible aspects of tasks, such as shapes, physics, and constraints.
Recent research spearheaded by a collaborative effort from Google Deepmind, MIT, and UC Berkeley has introduced a groundbreaking solution. They propose the amalgamation of text-to-video dynamics and vision-language models (VLMs) to mitigate these limitations. This integration, aptly named Video Language Planning (VLP), aims to streamline the process of visual planning for intricate, long-horizon activities. Leveraging the advancements in massive generative models pre-trained on vast datasets from the internet, VLP’s primary objective is to simplify the planning of tasks that demand extensive action sequences and comprehension spanning both the linguistic and visual domains. These tasks encompass a wide spectrum, ranging from elementary object rearrangements to intricate operations within robotic systems.
At the core of VLP lies a tree search procedure, comprising two pivotal components:
- Vision-Language Models: These multifaceted models play a dual role as both value functions and policy enforcers. They facilitate the creation and assessment of plans, guiding the next course of action based on their understanding of the task description and the available visual data.
- Models for Text-to-Video: These models function as dynamic predictors, foreseeing the potential consequences of decisions suggested by the vision-language models. They predict outcomes resulting from the behaviors recommended by the VLMs.
VLP relies on two primary inputs: a long-horizon task instruction and the current visual observations. The outcome is a comprehensive video-based plan that offers step-by-step instructions for achieving the ultimate objective, seamlessly merging language and visual cues. It effectively bridges the chasm between written task descriptions and visual comprehension.
The versatility of VLP is truly remarkable, encompassing a diverse array of tasks, from bi-arm dexterous manipulation to multi-object rearrangement. This adaptability underscores the vast potential applications of the approach. Real-world robotic systems can feasibly translate these generated video blueprints into tangible actions. Goal-conditioned rules play a pivotal role in this conversion, enabling the robot to methodically execute the task, leveraging each intermediate frame of the video plan as a guide for its actions.
Comparative experiments employing VLP against earlier techniques have yielded remarkable results. There have been substantial improvements in success rates for long-horizon tasks, with these experiments conducted on real robots across three distinct hardware platforms and in simulated environments.
Conclusion:
Video Language Planning (VLP) represents a transformative leap in the realm of robotics and AI, offering a pioneering solution to the intricate challenge of planning and executing long-horizon tasks. With its amalgamation of vision-language models and text-to-video dynamics, VLP paves the way for a future where robotic systems seamlessly navigate and interact with the physical world, opening up a multitude of possibilities for practical applications across industries.