
- Large language models (LLMs) struggle with processing extensive contexts due to Transformer-based architecture limitations.
- Enhancements in softmax attention, positional encodings, and retrieval-based methods have been explored to address these limitations.
- EM-LLM introduces episodic memory integration into Transformer-based LLMs, improving context handling capabilities.
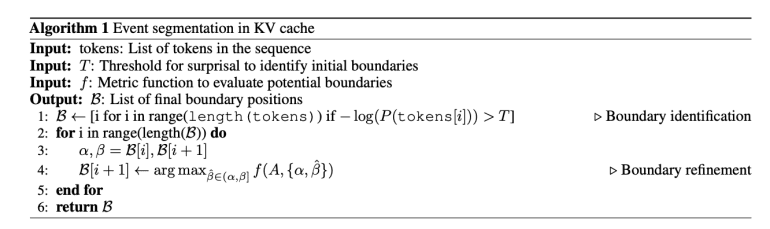
- The architecture categorizes context into initial tokens, evicted tokens, and local context, with a focus on surprise-based segmentation and temporal dynamics.
- EM-LLM showed significant performance improvements on long-context tasks compared to the InfLLM model, including gains in PassageRetrieval and HotpotQA tasks.
Main AI News:
Large language models (LLMs) face challenges in handling extensive contexts due to the limitations of Transformer-based architectures, which struggle to extend beyond their training window size. This constraint requires considerable computational resources and risks generating noisy attention embeddings, affecting the models’ ability to process domain-specific or up-to-date information. Despite various attempts, including retrieval-based methods, there remains a notable performance gap in tasks involving long contexts.
Researchers have focused on extending LLMs’ context windows by enhancing softmax attention, reducing computational costs, and improving positional encodings. Group-based k-NN retrieval has emerged as a promising technique, retrieving large token groups to act as hierarchical attention.
Simultaneously, insights from neural models of episodic memory highlight the significance of surprise-based event segmentation and temporal dynamics in memory processes. These models suggest that transformer-based LLMs exhibit similar temporal effects to human memory, offering potential for episodic memory retrieval with the right contextual information.
In response, researchers from Huawei Noah’s Ark Lab and University College London have introduced EM-LLM, an innovative architecture that integrates episodic memory into Transformer-based LLMs, significantly expanding their context handling capabilities. EM-LLM structures context into initial tokens, evicted tokens managed by an episodic memory model, and local context. By segmenting token sequences into events based on surprise levels and refining boundaries using graph-theoretic metrics, the model enhances cohesion and separation. It utilizes a two-stage memory retrieval mechanism: k-NN search for similar events and a contiguity buffer for maintaining temporal context, mimicking human episodic memory.
EM-LLM extends pre-trained LLMs to accommodate larger contexts by categorizing context into initial tokens, evicted tokens, and local context. The local context utilizes full softmax attention for recent information, while evicted tokens, akin to short-term episodic memory, handle past tokens. Fixed position embeddings are assigned to retrieved tokens outside the local context. This structure allows EM-LLM to effectively process beyond its pre-trained context window while maintaining performance.
Testing revealed EM-LLM’s superior performance on long-context tasks compared to the baseline InfLLM model. On the LongBench dataset, EM-LLM outperformed InfLLM in all but one task, achieving a 1.8 percentage point improvement overall. It showed notable enhancements in the PassageRetrieval task, with up to a 33% improvement, and a 9.38% improvement on the HotpotQA task. The results demonstrate EM-LLM’s improved capacity for recalling detailed information from extensive contexts and executing complex reasoning over multiple documents, with surprise-based segmentation methods aligning closely with human event perception.
Conclusion:
The development of EM-LLM signifies a major advancement in the capabilities of language models, particularly in handling extended contexts. By integrating episodic memory into Transformer-based architectures, EM-LLM addresses previous limitations and enhances performance in complex reasoning tasks. This innovation is likely to impact various sectors reliant on extensive data processing, including information retrieval, content generation, and AI-driven analytics. Organizations adopting EM-LLM could achieve more nuanced and effective use of large-scale text data, potentially leading to improved decision-making and competitive advantages. However, as the technology evolves, ongoing evaluation and adaptation will be necessary to fully leverage its capabilities and address any emerging challenges.