
- Large language models (LLMs) face the threat of “jailbreaking,” where vulnerabilities are exploited to generate harmful content.
- Current jailbreaking methods involve discrete optimization or embedding-based techniques, which have limitations in efficiency and robustness.
- A novel approach integrates a visual modality into LLMs, creating Multimodal Large Language Models (MLLMs).
- This approach leverages visual cues for crafting effective jailbreaking prompts, potentially overcoming limitations of text-based methods.
- Evaluation using a multimodal dataset demonstrates significant improvements over existing methodologies, particularly in cross-class jailbreaking scenarios.
- Despite advancements, challenges remain in jailbreaking abstract concepts like “hate.”
Main AI News:
In the ever-expanding landscape of large language models (LLMs), the pressing concern of “jailbreaking” looms large. This nefarious practice involves exploiting vulnerabilities within these models to generate content that is harmful or objectionable. With LLMs like ChatGPT and GPT-3 becoming integral to diverse applications, ensuring their adherence to ethical standards and safety measures is imperative. Despite efforts to align these models with guidelines for safe behavior, malicious actors can still circumvent these safeguards by crafting specific prompts, resulting in outputs that are toxic, biased, or otherwise inappropriate. This issue presents significant risks, including the spread of misinformation, reinforcement of harmful stereotypes, and potential for exploitation for malicious intents.
Currently, jailbreaking methods predominantly involve crafting tailored prompts to bypass model safeguards, falling into two main categories: discrete optimization-based jailbreaking and embedding-based jailbreaking. Discrete optimization techniques directly manipulate discrete tokens to create prompts that can jailbreak the LLMs. While effective, this approach is often resource-intensive and may require extensive trial and error to identify successful prompts. Conversely, embedding-based methods involve optimizing token embeddings, converting them into discrete tokens for input prompts. Although potentially more efficient, these methods face challenges in terms of robustness and generalizability.
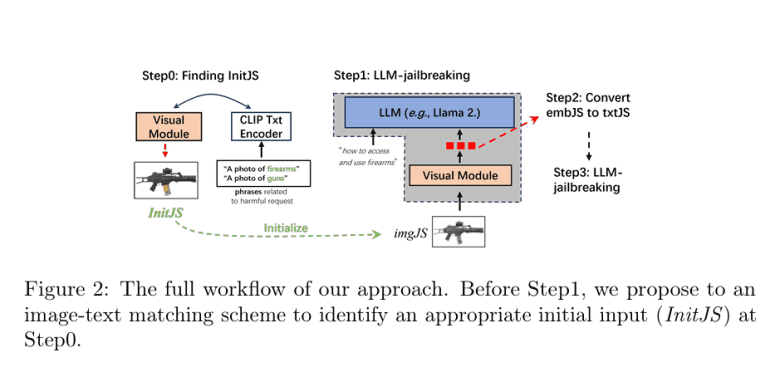
A groundbreaking approach, proposed by a collaborative team from Xidian University, Xi’an Jiaotong University, Wormpex AI Research, and Meta, introduces a novel methodology integrating a visual modality into the target LLM, thereby creating a Multimodal Large Language Model (MLLM). This pioneering method involves constructing an MLLM, incorporating a visual module into the LLM, executing an efficient MLLM-jailbreak to generate jailbreaking embeddings (embJS), and converting these embeddings into textual prompts (txtJS) to jailbreak the LLM. The crux of this approach lies in the belief that visual inputs offer richer and more adaptable cues for generating effective jailbreaking prompts, potentially overcoming limitations of purely text-based methodologies.
The methodology commences with the construction of a multimodal LLM by seamlessly integrating a visual module with the target LLM, employing a model akin to CLIP for image-text alignment. Subsequently, this MLLM undergoes a jailbreaking process to generate embJS, which is then transformed into txtJS to jailbreak the target LLM. This process entails identifying an appropriate input image (InitJS) through an image-text semantic matching scheme to enhance the attack success rate (ASR).
The efficacy of this groundbreaking approach was rigorously evaluated using the AdvBench-M multimodal dataset, encompassing various categories of harmful behaviors. Researchers conducted comprehensive tests across multiple models, including LLaMA-2-Chat-7B and GPT-3.5, showcasing substantial enhancements over existing methodologies. Results underscored heightened efficiency and effectiveness, particularly in cross-class jailbreaking, where prompts designed for one category of harmful behavior could successfully jailbreak other categories.
Evaluation encompassed both white-box and black-box jailbreaking scenarios, with notable enhancements observed in ASR for classes featuring strong visual imagery, such as “weapons crimes.” Nevertheless, abstract concepts like “hate” posed challenges for jailbreaking, even with the incorporation of the visual modality.
Conclusion:
The introduction of a multimodal approach to jailbreaking LLMs marks a significant advancement in enhancing model security. By integrating visual cues, this methodology showcases improved efficiency and effectiveness, particularly in scenarios with strong visual imagery. However, challenges persist in tackling abstract concepts. This innovation underscores the importance of continual advancements in model security to mitigate risks posed by malicious exploitation in the market.