
TL;DR:
- Mathematical reasoning in AI combines logical thinking with visual comprehension, offering practical applications.
- Current AI datasets lack comprehensive integration of visual language with math.
- Large Multimodal Models (LMMs) show promise but remain understudied for math reasoning in visuals.
- MATHVISTA benchmark, a collaborative effort by UCLA, the University of Washington, and Microsoft, features 6,141 examples from 28 datasets.
- The benchmark evaluates mathematical reasoning in various contexts and includes newly developed datasets.
- MATHVISTA comprises seven types of math reasoning, focusing on five core tasks in diverse visual settings.
- 12 foundation models, including LLMs and LMMs, undergo rigorous testing in the MATHVISTA framework.
- Bard, a multimodal model, achieves 34.8% accuracy, nearly 58% of human performance.
- GPT-4V, a multimodal version of GPT-4, leads with an accuracy of 49.9%, marking a significant improvement.
- Bard’s shortcomings include incorrect calculations and visual-textual reasoning issues.
Main AI News:
The Intersection of Mathematics and AI
Mathematical reasoning, a cornerstone of advanced cognition, delves into the intricate nuances of human intelligence. It encompasses logical thinking and specialized knowledge, extending beyond mere words to incorporate visual comprehension—a vital component for holistic understanding. The intersection of mathematics and artificial intelligence (AI) holds immense practical significance. However, existing AI datasets often fall short, narrowly focused and neglect the profound integration of visual language comprehension with mathematical reasoning.
Unraveling the Potential of Large Multimodal Models
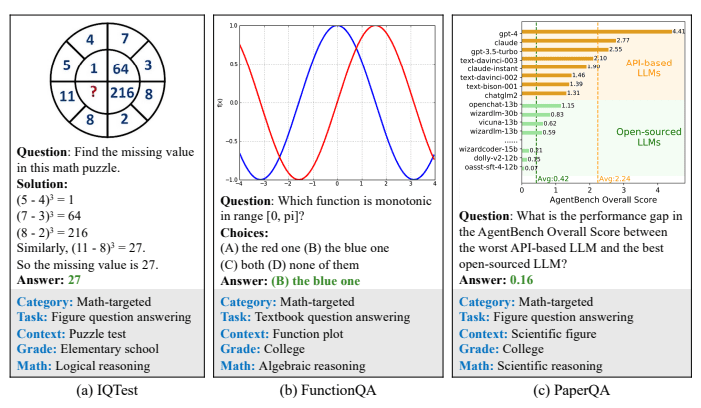
While Large Language Models (LLMs) and Large Multimodal Models (LMMs) have exhibited exceptional problem-solving capabilities across a wide spectrum of tasks, their prowess in mathematical reasoning within visual contexts remains an underexplored realm. To bridge this gap, a collaborative effort between researchers from UCLA, the University of Washington, and Microsoft has led to the inception of MATHVISTA—a benchmark that amalgamates challenges from diverse mathematical and visual tasks. This pioneering benchmark comprises a total of 6,141 examples, meticulously curated from 28 existing multimodal datasets pertaining to mathematics, supplemented by the introduction of three new datasets—IQTest, FunctionQA, and PaperQA.
Navigating Complex Tasks
Successful navigation of these tasks demands a nuanced grasp of visual intricacies and sophisticated compositional reasoning, presenting formidable challenges even for the most advanced foundation models.
Introducing MATHVISTA: A Comprehensive Benchmark
In their groundbreaking paper, the authors introduce MATHVISTA as a comprehensive benchmark tailored to assess mathematical reasoning within visual contexts. To guide its development, they propose a task taxonomy that identifies seven distinct types of mathematical reasoning, with a primary focus on five fundamental tasks:
- Figure Question Answering (FQA)
- Geometry Problem Solving (GPS)
- Math Word Problem (MWP)
- Textbook Question Answering (TQA)
- Visual Question Answering (VQA)
The benchmark encompasses a rich diversity of visual contexts, spanning natural images, geometry diagrams, abstract scenes, synthetic scenarios, figures, charts, and plots. MATHVISTA is a culmination of 28 existing multimodal datasets, comprising nine math-centric question-answering (MathQA) datasets and 19 VQA datasets, ensuring a comprehensive evaluation of mathematical reasoning capabilities.
Evaluating Leading Models
In their pursuit of excellence, researchers conducted exhaustive evaluations on 12 prominent foundation models. This lineup included three Large Language Models (LLMs) such as ChatGPT, GPT-4, and Claude-2, along with two proprietary Large Multimodal Models (LMMs)—GPT4V and Bard, in addition to seven open-source LMMs. These models underwent rigorous scrutiny within the MATHVISTA framework, utilizing zero-shot and few-shot settings, accompanied by chain-of-thought (CoT) and program-of-thought (PoT) prompting strategies.
Key Insights from MATHVISTA
The results brought to light intriguing revelations. CoT GPT-4, the top-performing text-based model devoid of visual enhancements, achieved an overall accuracy rate of 29.2%. In stark contrast, Bard, the leading multimodal model, demonstrated an impressive 34.8% accuracy, closely trailing human performance at 58% (34.8% vs. 60.3%). Notably, when PoT GPT-4 was enriched with Bard’s captions and OCR text, it surged to an accuracy rate of 33.9%, nearly matching the performance of the Multimodal Bard.
A Closer Look at Model Shortcomings
A deeper analysis revealed that Bard’s model deficiencies were rooted in incorrect calculations and hallucinations influenced by the interplay of visual perception and textual reasoning. In a significant development, GPT-4V, the latest multimodal iteration of GPT-4, emerged as the star performer, achieving a remarkable state-of-the-art accuracy rate of 49.9%. This marked a substantial 15.1% improvement over the Multimodal Bard—an achievement that stands as a testament to the evolving landscape of mathematical reasoning within multimodal AI systems.
Conclusion:
The MATHVISTA evaluation underscores the potential of multimodal AI models like GPT-4v and Bard in advancing mathematical reasoning within visual contexts. Their remarkable performance signifies a significant step toward enhancing AI capabilities in mathematical problem-solving and understanding. This development is poised to drive innovation and applications across industries, ranging from education to data analysis, opening up new avenues for AI integration in complex problem-solving scenarios.