
TL;DR:
- CRAG addresses the challenge of inaccuracies in large language models.
- Retrieval-augmented generation (RAG) is introduced to enhance LLMs with external knowledge.
- CRAG introduces a retrieval evaluator to assess the quality of retrieved documents.
- It utilizes a dynamic decompose-recompose algorithm to focus on relevant information.
- CRAG harnesses large-scale web searches to enrich its knowledge base.
- Rigorous testing demonstrates CRAG’s superiority over standard RAG approaches.
- CRAG sets a new standard for integrating external knowledge into language models.
Main AI News:
In the realm of natural language processing, the quest for precision in language models has sparked innovative approaches to mitigate the inherent inaccuracies that may arise. A significant challenge that has emerged is the propensity of these models to produce what can be termed as “hallucinations” or factual errors, often stemming from their reliance on internal knowledge bases. This issue is particularly pronounced in the realm of large language models (LLMs), despite their linguistic prowess, especially when generating content that must align with real-world facts.
Enter the concept of retrieval-augmented generation (RAG), a novel approach designed to bolster LLMs by seamlessly integrating external, pertinent knowledge during the generation process. However, the effectiveness of RAG hinges significantly on the accuracy and relevance of the retrieved documents. This leads us to a crucial question: what happens when the retrieval process falls short, introducing inaccuracies or irrelevant information into the generative process?
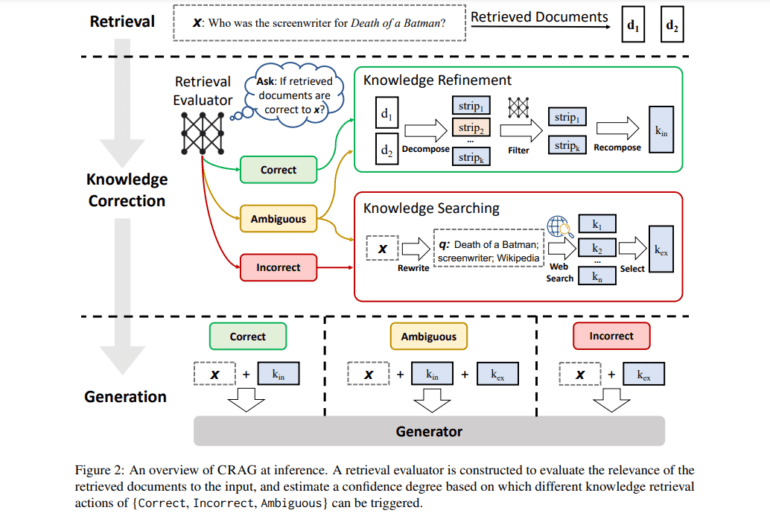
Meet Corrective Retrieval Augmented Generation (CRAG), an innovative methodology conceived by researchers to fortify the generation process against the pitfalls of inaccurate retrieval. At its core, CRAG introduces a lightweight retrieval evaluator, a mechanism meticulously crafted to assess the quality of retrieved documents for any given query. The evaluator plays a pivotal role, offering a nuanced understanding of the relevance and reliability of the retrieved documents. Based on its assessments, the evaluator can initiate various knowledge retrieval actions, ultimately enhancing the robustness and accuracy of the generated content.
What sets CRAG apart is its dynamic approach to document retrieval. CRAG doesn’t simply acknowledge shortcomings when the evaluation deems the retrieved documents suboptimal. Instead, it deploys a sophisticated decompose-recompose algorithm, strategically focusing on the essence of the retrieved information while discarding extraneous details. This meticulous process ensures that only the most relevant and accurate knowledge is seamlessly integrated into the generation process. Furthermore, CRAG embraces the vastness of the web, harnessing large-scale searches to expand its knowledge base beyond static, limited corpora. This not only broadens the spectrum of retrieved information but also elevates the quality of the generated content.
The efficacy of CRAG has undergone rigorous testing across multiple datasets, encompassing both short- and long-form generation tasks. The results unequivocally demonstrate CRAG’s superiority over standard RAG approaches, underscoring its prowess in navigating the complexities of accurate knowledge retrieval and integration. This superiority is especially apparent in its application to short-form question answering and long-form biography generation, where precision and depth of information are paramount.
Conclusion:
These advancements represent a significant leap forward in the quest for more reliable and accurate language models. CRAG’s unparalleled ability to refine the retrieval process, ensuring high relevance and reliability in the external knowledge it leverages, signifies a monumental achievement. This methodology not only addresses the immediate challenge of “hallucinations” in LLMs but also establishes a new standard for the seamless integration of external knowledge in the generation process.