
- Transformers excel in NLP and computer vision but face scalability issues with graph data.
- AnchorGT selects “anchor” nodes strategically, reducing computational load while preserving global information.
- The attention mechanism is revamped to include local neighbors and the anchor set, enhancing expressiveness.
- Theoretical and empirical evaluations demonstrate AnchorGT’s superiority over traditional graph neural networks.
- AnchorGT variants outperform original Transformer models while being more memory-efficient and faster.
Main AI News:
The realm of machine learning has been revolutionized by Transformers, with their remarkable self-attention mechanism propelling them to the forefront of natural language processing and computer vision. However, their application to graph data, pervasive in fields such as social networks, biology, and chemistry, has been impeded by the quadratic computational complexity scaling with graph node count, posing a significant bottleneck.
To surmount this obstacle, previous endeavors have explored techniques like sampling or linear attention approximations directly applied to graph Transformers. Yet, these approaches are not without flaws. Sampling sacrifices global receptive field advantage, while linear approximations clash with common relative structural encodings, hindering the model’s capacity to learn graph structures.
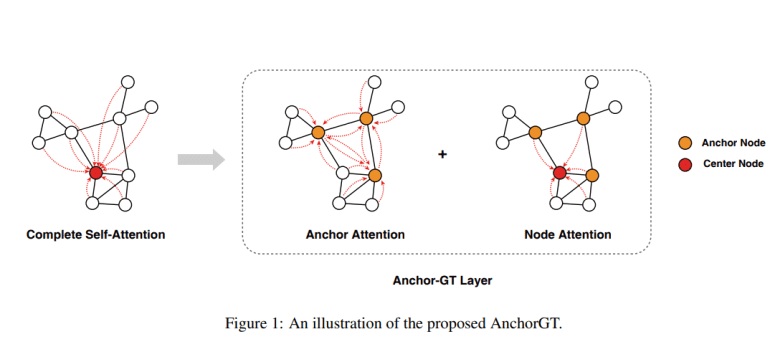
In response, a team of researchers has proposed AnchorGT, a pioneering solution showcased in this study, which tackles scalability challenges while preserving Transformer expressiveness. The concept is elegantly simple: rather than enabling each node to attend to every other node, AnchorGT strategically selects a subset of “anchor” nodes, serving as information hubs. This approach drastically reduces computational load while retaining global information.
Leveraging the graph theory concept of “k-dominating set,” AnchorGT efficiently selects anchor nodes. These nodes ensure that every graph node is within a certain hop distance, facilitating effective information flow. The attention mechanism is then revamped, with each node attending to its local neighbors and the anchor set. Structural information is injected using relative encodings, enhancing model expressiveness.
Theoretically, AnchorGT surpasses traditional graph neural networks in expressiveness, as demonstrated through rigorous testing against the Weisfeiler-Lehman test. Empirical evaluations on datasets such as QM9, Citeseer, and Pubmed affirm the superior performance and efficiency of AnchorGT variants over original Transformer models.
For instance, Graphormer-AnchorGT on the ogb-PCQM4Mv2 dataset outperforms its predecessor while utilizing 60% less GPU memory during training. Scalability advantages are further highlighted through experiments on Erdős-Rényi random graphs, showcasing near-linear memory scaling compared to quadratic blowup in standard Transformers.
AnchorGT’s success lies in its ability to optimize computational efficiency without sacrificing expressive power. By introducing anchor nodes and refining the attention mechanism, researchers have made significant strides in enabling Transformer applicability to large-scale graph data, promising advancements across diverse domains.
Conclusion:
The introduction of AnchorGT represents a significant advancement in graph Transformer models, addressing scalability challenges without compromising expressiveness. This innovation opens doors for broader applications of Transformers across industries reliant on graph-structured data, promising increased efficiency and performance in various domains. Businesses should take note of these developments and explore opportunities to leverage AnchorGT for enhanced data processing and analysis.