
- Alignment strategies crucial for LLM safety, combining DPO, RLHF, and SFT.
- Vulnerabilities found: adversarial inputs, fine-tuning changes, decoding parameter tampering.
- Recent study exposes shallow safety alignment flaw, leaving models open to exploits.
- Initial tokens heavily influence safety behaviors, affecting susceptibility to attacks.
- Proposed solutions: extending alignment techniques, data augmentation, focused optimization.
- Current approaches relatively shallow, leading to known vulnerabilities.
Main AI News:
In the realm of Artificial Intelligence (AI), ensuring the alignment of strategies is paramount for the safety of Large Language Models (LLMs). These methodologies often amalgamate preference-based optimization techniques like Direct Preference Optimization (DPO) and Reinforcement Learning with Human Feedback (RLHF) alongside supervised fine-tuning (SFT). By adapting the models to steer clear of hazardous inputs, such strategies aim to diminish the probability of generating harmful content.
However, recent investigations have unearthed several vulnerabilities in these alignment strategies. For instance, adversarial optimizations, minor fine-tuning adjustments, or tinkering with the model’s decoding parameters can still deceive aligned models into responding to malicious inquiries. Given the pivotal role alignment plays in ensuring LLM safety, understanding the root causes of these weaknesses in existing safety alignment protocols is imperative, along with devising viable solutions to address them.
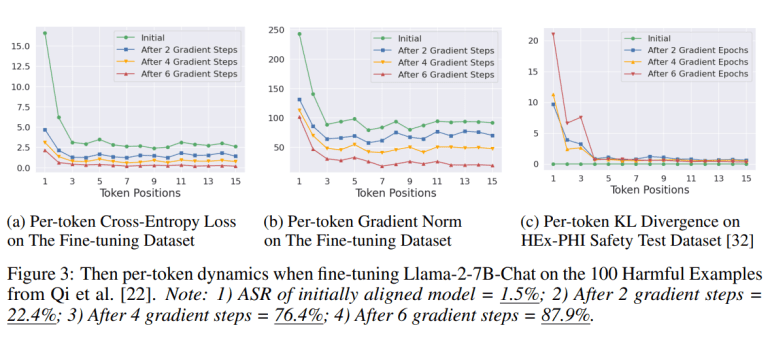
A recent collaborative study between researchers from Princeton University and Google DeepMind has pinpointed a fundamental flaw in current safety alignment methodologies, rendering models particularly susceptible to relatively straightforward exploits. It appears that alignment predominantly affects the model’s initial tokens, a phenomenon termed as shallow safety alignment. Consequently, the entirety of the generated output could veer into hazardous territories if the model’s initial output tokens deviate from safe responses.
Through methodical experimentation, the research demonstrates that the initial tokens of aligned and unaligned models exhibit the most significant variance in safety behaviors. This shallow alignment explains the efficacy of certain attack methods, particularly those that initiate destructive trajectories. Notably, adversarial suffix attacks and fine-tuning attacks frequently induce drastic alterations in the original tokens of a destructive reaction.
Furthermore, the study illustrates how merely altering these initial tokens can reverse the model’s alignment, highlighting the precarious nature of even minor model adjustments. To address this issue, the team advocates for extending alignment techniques deeper into the output. They introduce a data augmentation method that leverages safety alignment data to train models, transforming potentially damaging responses into safe rejections.
By widening the disparity between aligned and unaligned models at deeper token levels, this approach aims to bolster resilience against commonly employed exploits. Additionally, to mitigate the impact of fine-tuning attacks, the study proposes a focused optimization objective aimed at averting substantial shifts in initial token probabilities. This strategy underscores the shallow nature of current model alignments and offers a potential defense mechanism against fine-tuning attacks.
Conclusion:
The findings highlight the pressing need to fortify security measures surrounding Large-Scale Language Models (LLMs). With vulnerabilities exposed in existing alignment strategies, there’s a call for heightened vigilance and innovation within the market. Addressing these weaknesses could not only safeguard against potential risks but also foster greater trust and adoption of LLM technologies in various sectors.