
TL;DR:
- ETH Zurich researchers simplify deep Transformers while preserving performance.
- Signal propagation theory and empirical observations inform modifications.
- Skip connections, projection parameters, and normalization layers are removed.
- Simplified transformers achieve comparable performance with 15% fewer parameters.
- Significant potential to reduce the cost of large transformer models.
- Future research may explore effects on larger models, hyperparameter optimization, and hardware-specific implementations.
Main AI News:
In the realm of cutting-edge artificial intelligence research, a groundbreaking study emanating from ETH Zurich delves deep into the intricate balance between design complexity and performance in the domain of deep Transformers. This seminal research effort, characterized by its unwavering commitment to simplification without compromising efficiency, presents a promising avenue for the evolution of deep neural networks.
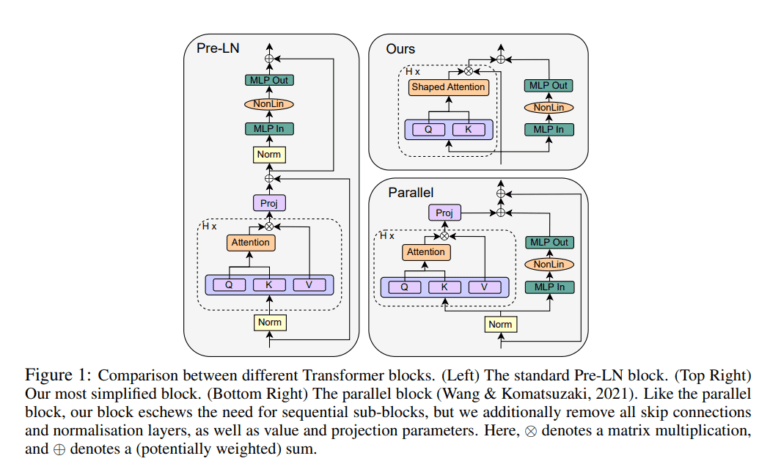
At the core of this investigation lies a meticulous examination of the standard transformer block. Inspired by signal propagation theory, the researchers scrutinize the arrangement of building blocks, integrating attention and MLP sub-blocks replete with skip connections and normalization layers. A novel addition to the arsenal is the introduction of the parallel block, designed to compute MLP and attention sub-blocks concurrently, ushering in improved efficiency.
Intriguingly, the study goes beyond the surface and probes the very essence of transformer blocks, questioning the necessity of various components within. It ventures boldly into the uncharted territory of removing these components, all while maintaining the blazing training speed that is quintessential to the performance of modern deep neural networks.
Fueling this bold journey is a fusion of signal propagation theory and empirical observations, yielding a trove of modifications aimed at simplifying transformer blocks. The researchers subjected these simplified transformers to rigorous experimentation, encompassing autoregressive decoder-only and BERT encoder-only models. These experiments probed the effects of removing skip connections within the attention sub-block, shedding light on the resulting signal degeneracy.
The results of this pioneering work are nothing short of astonishing. The proposed modifications succeed in simplifying transformer blocks by eliminating skip connections, projection/value parameters, sequential sub-blocks, and normalization layers. Astonishingly, these modifications do not merely maintain the status quo; they enhance it. Standard transformers’ training speed and performance remain unscathed, yet they are now accomplished with fewer parameters and a remarkable boost in training throughput.
To put it into numerical perspective, the proposed simplified transformers manage to rival their standard counterparts in performance while exhibiting a 15% reduction in parameters and a corresponding 15% surge in training throughput. This is no trifling achievement; it paves the way for simplified deep-learning architectures that promise to alleviate the financial burden of employing large transformer models.
The experimental validation of these simplifications spans various settings, underscoring their effectiveness. Moreover, the study highlights the pivotal role played by initialization methods in optimizing the performance of simplified transformers, opening avenues for further exploration in this regard.
As we look ahead to the future of research in this domain, the study leaves us with tantalizing prospects. It calls for a more comprehensive investigation of the proposed simplifications on larger transformer models beyond the scope of its current focus on relatively modest ones. Moreover, it beckons us to undertake a thorough hyperparameter search, custom-tailored to extract the full potential of these simplified blocks. Lastly, it encourages exploration into hardware-specific implementations, hinting at the promise of even more remarkable improvements in training speed and performance. The road ahead, it seems, is laden with exciting possibilities, all thanks to the pioneering work of ETH Zurich’s researchers.
Conclusion:
ETH Zurich’s research on simplifying transformers marks a significant stride in the field of deep neural networks. Their approach, guided by signal propagation theory, results in streamlined models that not only maintain performance but also enhance training throughput. This innovation has the potential to revolutionize the market by reducing the cost of large transformer models, making them more accessible and cost-effective for businesses and organizations seeking to leverage advanced AI capabilities.