
- EURUS represents a collaborative effort aimed at advancing large language models (LLMs) for superior reasoning capabilities.
- Current LLMs face challenges due to the scarcity of alignment data and underutilization of preference learning strategies.
- Specialized models like MAmmoTH-7B-Mistral and Magicoder-S-DS-6.7B cater to mathematical reasoning and coding proficiency, respectively.
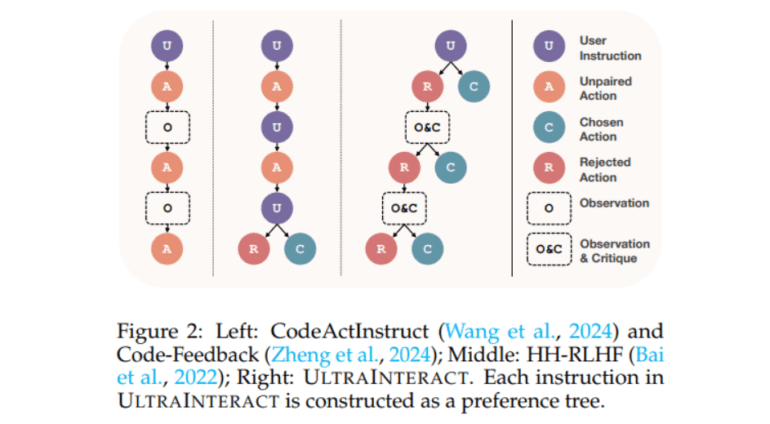
- EURUS introduces ULTRA INTERACT, a dataset enhancing reasoning through preference learning and intricate interaction models.
- The methodology employs supervised fine-tuning, preference learning, and a novel reward modeling objective.
- EURUS-70B achieves remarkable performance, surpassing existing models by significant margins across diverse benchmarks.
Main AI News:
The transformative impact of large language models (LLMs) on the landscape of Artificial Intelligence (AI) cannot be overstated. These models have emerged as indispensable tools, proficient not only in understanding natural language but also in tackling intricate mathematical conundrums and generating code. Central to their prowess is the ability to reason effectively—employing logical processing to resolve problems, make informed decisions, and extract valuable insights. Yet, despite their remarkable capabilities, LLMs encounter challenges, chiefly stemming from the scarcity of high-quality alignment data and underutilization of preference learning strategies aimed at bolstering their complex reasoning faculties.
Current endeavors have led to the development of specialized LLMs like MAmmoTH-7B-Mistral and WizardMath-7B-v1.1, focusing on mathematical reasoning, and Magicoder-S-DS-6.7B and OpenCodeInterpreter (OpenCI-DS-6.7B/CL-70B) catering to coding proficiency. Moreover, innovations in preference learning techniques, such as DPO and KTO methods, have aimed to align models more closely with human preferences. However, a critical gap persists in fostering unified reasoning capabilities across diverse domains—a proficiency that proprietary models like GPT-3.5 Turbo and GPT-4 exhibit more adeptly. This underscores the need for advancing broad-based reasoning abilities within the open-source LLM ecosystem.
EURUS emerges as a collaborative endeavor, drawing expertise from researchers at Tsinghua University, the University of Illinois Urbana-Champaign, Northeastern University, Renmin University of China, and ModelBest.Inc, BUPT, and Tencent. This concerted effort has yielded a suite of LLMs finely tuned for enhanced reasoning. What distinguishes EURUS is its innovative utilization of ULTRA INTERACT, a meticulously curated dataset designed to augment reasoning capabilities through preference learning and sophisticated interaction models. This novel methodology empowers EURUS to outshine its predecessors in reasoning tasks, showcasing its prowess in addressing complex challenges.
The EURUS methodology hinges on supervised fine-tuning and preference learning, harnessing the potential of the ULTRA INTERACT dataset. This comprehensive dataset amalgamates preference trees with reasoning chains, multi-turn interaction trajectories, and paired actions, fostering nuanced reasoning training. Leveraging foundational models like Mistral-7B and CodeLlama-70B, the fine-tuning process culminates in performance evaluations across benchmarks such as LeetCode and TheoremQA, gauging reasoning prowess across mathematical and code generation tasks. Furthermore, a novel reward modeling objective, informed by insights gleaned through preference learning, enhances EURUS’s decision-making accuracy, positioning it as a frontrunner in reasoning tasks.
EURUS-70B has demonstrated remarkable reasoning capabilities, attaining a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA. These results markedly surpass those of existing open-source models, eclipsing them by margins exceeding 13.3%. This exemplary performance across diverse benchmarks, spanning mathematics and code generation tasks, underscores EURUS’s efficacy in addressing complex reasoning challenges. In essence, EURUS establishes a new paradigm in LLM performance, setting benchmarks for both mathematical and coding problem-solving tasks.
Conclusion:
EURUS signifies a significant leap forward in the realm of large language models, addressing critical challenges and setting new standards for reasoning capabilities. Its innovative approach, underscored by the utilization of advanced datasets and methodologies, signals a promising direction for the market. As EURUS outperforms existing models across various domains, businesses and industries can anticipate heightened efficiency and accuracy in tasks reliant on natural language processing and reasoning, thereby enhancing overall productivity and innovation within the AI landscape.