
TL;DR:
- Stanford and Cornell’s researchers propose EVAPORATE, a revolutionary method to reduce the inference cost of language models by 110x.
- Language models’ training cost is high due to their large number of parameters and training on trillions of tokens.
- EVAPORATE focuses on reducing inference costs and improving quality in processing large documents.
- The approach involves prompting the language model to extract values directly from documents or synthesize code for extraction.
- The team identifies tradeoffs between cost and quality, favoring individual document processing for higher accuracy.
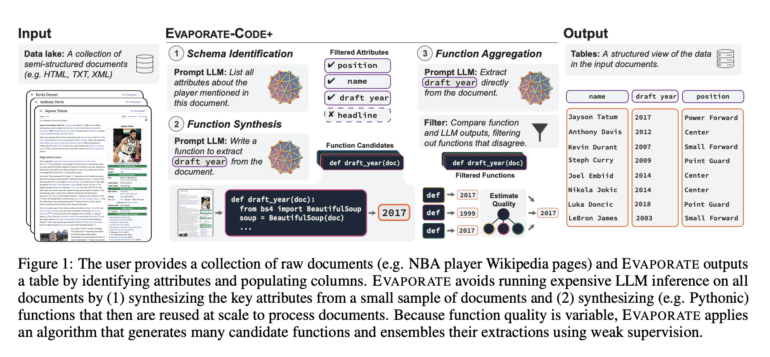
- EVAPORATE exploits redundancies across documents to improve efficiency, generating reusable functions for extraction.
- EVAPORATE-CODE+ extends code synthesis, generating multiple candidate functions and leveraging weak supervision.
- The evaluation shows EVAPORATE-CODE+ outperforms existing systems, reducing the number of tokens processed by 110x.
- The research presents a promising method for automating table extraction from semi-structured documents using language models.
Main AI News:
The remarkable capabilities of large language models (LLMs) have undoubtedly captured widespread attention in recent times. These models, with their wide-ranging applications across various domains, continue to be at the forefront of cutting-edge research and development. However, the exorbitant cost associated with training LLMs remains a significant challenge. With an extensive number of parameters and training on trillions of tokens, the expenses involved are staggering.
Addressing this critical issue, a group of students from Stanford University and Cornell University has unveiled a groundbreaking solution in their latest research paper. This innovative approach tackles the problem of costly LLMs by focusing on the inference stage. The research team sheds light on how language models become particularly expensive when processing extensive documents. They cite the astounding cost of running inference over a staggering 55 million Wikipedia pages, amounting to over $100,000. This equates to an astonishing price of more than $0.002 per 1000 tokens. To combat this, the authors propose a method capable of reducing inference costs by a remarkable factor of 110, all while enhancing the quality of results compared to conventional inference methods.
Dubbed EVAPORATE, this novel system harnesses the power of LLMs and introduces two distinct strategies for implementation. The first strategy involves prompting the LLM to directly extract values from documents, while the second entails prompting the LLM to synthesize code for performing the extraction. Through thorough evaluation, the research team discovered a tradeoff between cost and quality when employing these two approaches. While code synthesis proved to be more cost-effective, it was found to be less accurate than processing each document individually using the LLM.
EVAPORATE leverages redundancies across multiple documents to achieve heightened efficiency. The researchers provide an illustrative example of this concept by extracting the device classification attribute from FDA reports on medical devices. Instead of processing each semi-structured document individually, they explore the possibility of utilizing the LLM to generate reusable functions for extraction purposes.
To simultaneously enhance quality and reduce costs, the team introduces an extended implementation of code synthesis, known as EVAPORATE-CODE+. This approach generates numerous candidate functions and combines their extractions using weak supervision. While weak supervision is typically applied to human-generated functions, EVAPORATE-CODE+ operates with machine-generated functions, addressing the inherent challenges of this setup and enabling significant improvements in quality.
The performance of EVAPORATE has been meticulously evaluated across 16 sets of documents encompassing a wide range of formats, topics, and attribute types. Notably, EVAPORATE-CODE+ surpasses the state-of-the-art systems by employing a sublinear pass over the documents with the LLM. As a result, there is a remarkable 110-fold reduction in the number of tokens that the LLM needs to process, averaging across the 16 evaluation settings of 10,000 documents each.
Conclusion:
The introduction of EVAPORATE represents a significant breakthrough in the market. By reducing the inference cost of language models by a remarkable factor of 110, this method addresses the longstanding challenge of expensive training costs. The ability to process large documents with improved quality and efficiency opens up new possibilities for data management and analysis. EVAPORATE’s impact extends beyond academia, providing businesses with a cost-effective solution for automating the extraction of valuable information from semi-structured documents. This advancement is poised to drive innovation, streamline operations, and enhance decision-making processes in various industries that heavily rely on language models and document processing. As organizations seek to maximize the value of their data, EVAPORATE offers a promising avenue for unlocking actionable insights while minimizing costs.