
- Exabits and MyShell collaborated to drastically reduce LLM training costs from billions to under $100,000.
- JetMoE-8B model achieves superior performance at a fraction of the cost compared to competitors like Meta AI’s LLaMA2-7B.
- MyShell’s innovative JetMoE-8B model boasts 8 billion parameters and a sophisticated structure, showcasing efficiency and computational intelligence.
- Exabits’ contribution of an accelerated and stabilized GPU cluster played a pivotal role in powering JetMoE-8B, ensuring robust performance at reduced costs.
- Exabits disproved skepticism surrounding decentralized GPU platforms for LLM training, showcasing efficiency and cost-effectiveness.
- The success of Exabits and MyShell’s collaboration signifies a paradigm shift in LLM training, fostering affordability, accessibility, and environmental consciousness.
Main AI News:
In a remarkable partnership, Exabits and MyShell have shattered barriers in the realm of large language model (LLM) training costs, transforming a multi-billion dollar endeavor into a venture achievable for under $100,000. Exabits’ prowess in training large language models (LLMs) has joined forces with MyShell, yielding groundbreaking results that redefine the economics of sophisticated AI development.
MyShell’s JetMoE-8B model, crafted at a fraction of traditional costs, has not only redefined expectations but has also surpassed established benchmarks. Inspired by the sparse activation architecture of ModuleFormer, MyShell’s achievement symbolizes a significant milestone in machine learning advancement. With 8 billion parameters meticulously structured across 24 blocks housing two MoE layers each, JetMoE-8B epitomizes efficiency and computational prowess. The selective activation mechanism, enabling 2 out of 8 experts per input token, demonstrates a refined utilization of the Sparse Mixture of Experts (SMoE) framework, elevating responsiveness and resource management to unprecedented levels.
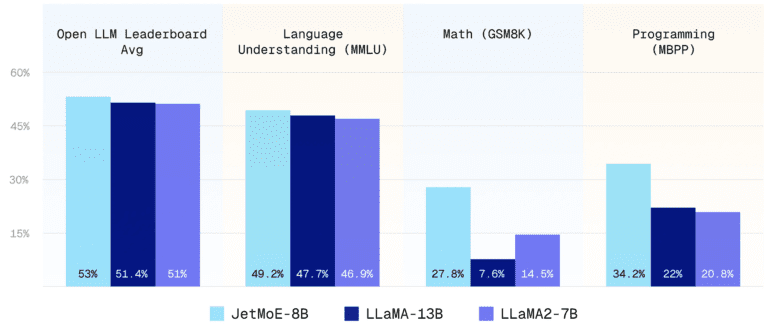
Moreover, the efficiency of JetMoE-8B, with its 2.2 billion activation parameters, has significantly slashed training costs while delivering robust performance. Surpassing competitors like LLaMA-13B, LLaMA2-7B, and DeepseekMoE-16B, JetMoE-8B has set new standards across multiple evaluation benchmarks, showcasing its dominance in the field of AI.
Fueling this architectural marvel is Exabits’ accelerated and stabilized cluster of 12 H100 GPU nodes (96 GPUs), which played a pivotal role in powering the JetMoE model. Exabits’ contribution ensures stable, ultra-available, and robust performance, all at a fraction of the cost typically associated with large-scale computational endeavors. This synergy between JetMoE’s innovative design and Exabits’ cutting-edge GPU technology epitomizes a monumental leap in machine learning capabilities, while also underscoring the efficacy of integrating advanced model architectures with Exabits’ cloud compute infrastructure.
The Myth Dispelled: Decentralized GPU Platforms Revolutionize LLM Training
Exabits has effectively debunked the skepticism surrounding the suitability of decentralized GPU platforms for LLM training. By leveraging a sophisticated technical stack, efficient middleware, and a robust supply chain of computational resources, Exabits has showcased the viability and efficiency of LLM training and inference on decentralized platforms.
Functioning as a decentralized cloud compute platform, Exabits overcomes the limitations of traditional decentralized platforms by serving as the foundational infrastructure layer of AI computing. By aggregating, accelerating, and stabilizing consumer-grade GPUs, Exabits ensures performance comparable to enterprise-grade GPUs, thereby mitigating the GPU shortage crisis and democratizing access to AI development. Partnerships with key players in decentralized cloud compute further bolster Exabits’ position, establishing a widespread, interconnected decentralized compute network poised to rival centralized cloud computing giants.
The Future of LLM Training: A Paradigm Shift with Exabits
Exabits isn’t merely a technological platform; it’s a harbinger of the future of LLM training, embodying principles of affordability, accessibility, and environmental consciousness. The success of JetMoE-8B serves as a testament to the platform’s potential to revolutionize high-end model training, fostering a more sustainable and inclusive landscape for AI research and development.
Conclusion:
The collaboration between Exabits and MyShell marks a significant milestone in the field of AI, particularly in LLM training. By revolutionizing cost-efficiency and performance standards, they have opened doors to a more inclusive and sustainable landscape for AI research and development. This breakthrough not only challenges traditional norms but also paves the way for greater accessibility and innovation in the market. Businesses should take note of these advancements as they signal a shift towards more efficient and scalable AI solutions.