
TL;DR:
- Large language models (LLMs) face challenges due to high computational costs.
- Mixture of Experts (MoE) models offer a solution by dynamically allocating tasks to specialized subsets.
- Researchers explore scaling laws for MoE models, focusing on granularity as a key parameter.
- Findings challenge conventional practices, showing MoE models outperform dense transformers with optimal configuration.
- MoE models demonstrate superior efficiency and scalability, reducing financial and environmental costs.
Main AI News:
In the realm of cutting-edge large language models (LLMs), significant strides have been made, revolutionizing various sectors with their unparalleled linguistic processing and generation capabilities. However, the substantial computational overhead required to train these mammoth models has triggered concerns regarding both financial feasibility and environmental sustainability. In response to these challenges, a paradigm shift is underway, focusing on leveraging Mixture of Experts (MoE) models to optimize training efficiency while maintaining peak model performance.
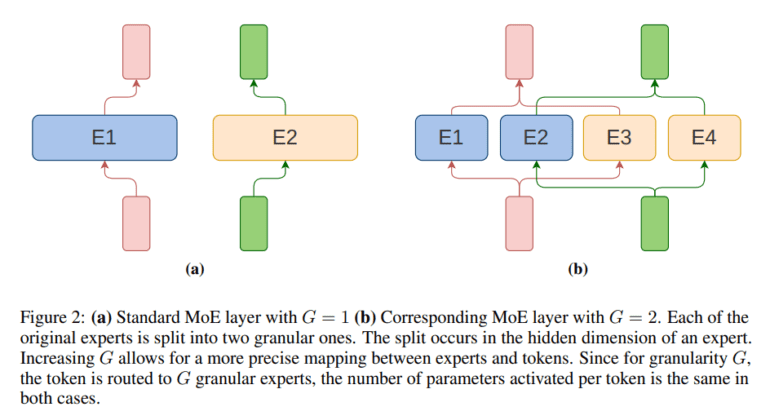
MoE models represent a novel approach by dynamically assigning tasks to specialized subsets within the model, referred to as experts. This innovative strategy optimizes computational resources by activating only relevant segments of the model for specific tasks, thereby streamlining efficiency. A consortium of researchers from esteemed institutions, including the University of Warsaw, IDEAS NCBR, IPPT PAN, TradeLink, and Nomagic, has embarked on a groundbreaking exploration into the scaling dynamics of MoE models. Central to their investigation is the concept of granularity as a pivotal hyperparameter, offering precise control over expert size and consequently enhancing computational efficiency.
Their study ventures into uncharted territory by formulating novel scaling laws for MoE models, taking into account an array of variables such as model size, training token count, and granularity. This analytical framework provides invaluable insights into optimizing training configurations to achieve maximum efficiency within specified computational constraints. Notably, their findings challenge established norms, particularly the prevalent practice of equating the size of MoE experts with the feed-forward layer dimensions, revealing such configurations to be suboptimal in practice.
The researchers present compelling evidence that finely tuned MoE models, calibrated with appropriate granularity settings, consistently outperform dense transformer models across various computational budgets. This efficiency gap widens with increasing model size and computational allocation, underscoring the transformative potential of MoE models in shaping the future of LLM training methodologies.
Key insights gleaned from this seminal study include:
- The ability to fine-tune expert size within MoE models through the manipulation of this innovative hyperparameter can significantly enhance computational efficiency.
- The development of scaling laws incorporating granularity and other essential variables provides a strategic blueprint for optimizing MoE models, ensuring superior performance and efficiency compared to traditional dense transformer models.
- Contrary to conventional wisdom, matching the size of MoE experts with the feed-forward layer dimensions is not optimal, necessitating a more nuanced approach to model configuration.
- When appropriately configured, MoE models exhibit superior efficiency and scalability compared to dense models, particularly at larger scales and computational budgets, thereby mitigating the financial and environmental costs associated with LLM training.
Conclusion:
The exploration of scaling laws for Mixture of Experts (MoE) models signifies a significant breakthrough in the landscape of large language models (LLMs). By optimizing computational efficiency through granular control over task allocation, MoE models offer a promising solution to the challenges posed by high training costs. This development has profound implications for the market, as it not only enhances the performance of language models but also addresses concerns related to financial feasibility and environmental sustainability. As organizations seek more efficient and sustainable solutions for natural language processing tasks, the adoption of MoE models is likely to gain momentum, shaping the future landscape of LLM technologies and applications.