
TL;DR:
- Information extraction (IE) in Natural Language Processing (NLP) is essential for structured knowledge.
- Large Language Models (LLMs) like Llama are transforming NLP with their text understanding and generation abilities.
- Generative IE using LLMs is gaining popularity for its efficiency in handling vast entity schemas.
- A study by leading institutions explores LLMs for generative IE, offering novel taxonomies and performance evaluations.
- LLMs excel in NER and RE but face challenges in EE tasks.
- Future research should focus on cross-domain learning and data annotation improvements.
- Enhancing prompts and interactive designs hold promise for better model comprehension and reasoning.
Main AI News:
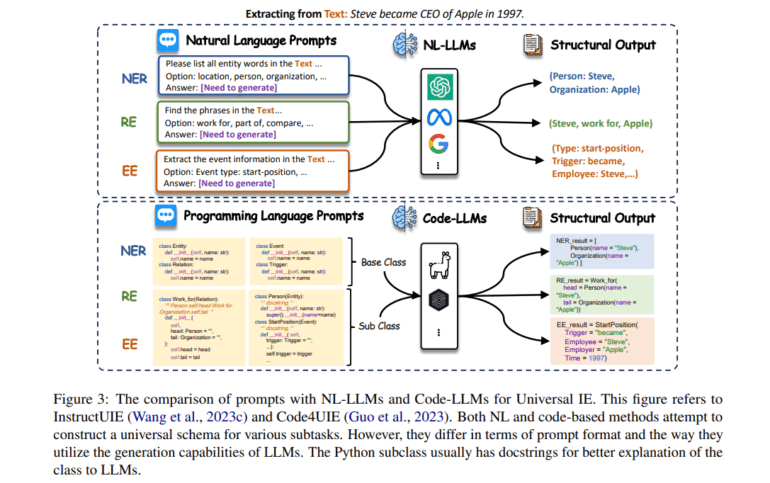
In the realm of Natural Language Processing (NLP), information extraction (IE) stands as a cornerstone, transforming unstructured text into organized knowledge. Countless subsequent endeavors in the NLP field rely on IE as a fundamental prerequisite, encompassing the construction of knowledge graphs, knowledge-based reasoning, and answering intricate queries. Within the realm of IE, three pivotal components emerge: Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Simultaneously, the advent of Large Language Models (LLMs), exemplified by the likes of Llama, has ushered in a paradigm shift, revolutionizing NLP with their unparalleled text comprehension, generation, and generalization capabilities.
Rather than extracting structured information from raw text, recent trends have witnessed the ascension of generative IE approaches harnessing LLMs to craft structured data. These innovative methods exhibit the remarkable prowess to efficiently manage schemas containing millions of entities, all without sacrificing performance, thereby outshining discriminative approaches in real-world applications.
A groundbreaking study conducted by the University of Science and Technology of China, in collaboration with the State Key Laboratory of Cognitive Intelligence at the City University of Hong Kong and the Jarvis Research Center, delves into the domain of generative IE with LLMs. This ambitious endeavor classifies contemporary representative techniques primarily through the lens of two taxonomies:
- A taxonomy of learning paradigms, which categorizes novel approaches utilizing LLMs for generative IE.
- A taxonomy of numerous IE subtasks, striving to categorize diverse types of information extractable individually or collectively through LLMs.
Furthermore, the study introduces a comprehensive ranking system for LLMs in the context of IE, assessing their performance across specific domains. An insightful analysis of the limitations and prospects of applying LLMs for generative IE is presented, accompanied by a thorough evaluation of representative approaches across diverse scenarios. It is worth noting that this survey, spearheading generative IE with LLMs, marks a pioneering effort in its domain.
The paper puts forth four Named Entity Recognition (NER) reasoning strategies that emulate ChatGPT’s zero-shot NER capabilities, capitalizing on the superior reasoning abilities inherent in LLMs. Some recent research endeavors in LLMs for Relation Extraction (RE) have revealed that few-shot prompting with models like GPT-3 attains performance levels nearly on par with the state-of-the-art. Furthermore, GPT-3-generated chain-of-thought explanations have been shown to enhance Flan-T5. However, challenges persist in Event Extraction (EE) tasks, as they demand intricate instructions and exhibit a lack of resilience. Similarly, various IE subtasks are concurrently scrutinized by researchers, revealing that while ChatGPT excels in the OpenIE environment, it often falls short when compared to BERT-based models in traditional IE settings. Additionally, a soft-matching approach highlights “unannotated spans” as the most common error type, emphasizing potential issues with data annotation quality and advocating for more precise evaluations.
Historically, generative IE approaches and benchmarks have often remained domain or task-specific, limiting their applicability in practical scenarios. Recent innovations have proposed unified techniques employing LLMs, yet they still grapple with substantial constraints, such as extended context input and unaligned structured output. As a remedy, researchers advocate a deeper exploration of LLMs’ in-context learning, especially in the context of enhancing example selection processes and crafting versatile IE frameworks adaptable to diverse domains and applications. They assert that future endeavors should prioritize the development of robust cross-domain learning methods, including domain adaptation and multi-task learning, to harness the full potential of resource-rich domains. Additionally, exploring effective data annotation systems integrating LLMs is deemed crucial.
Enhancing prompts to facilitate superior model comprehension and reasoning, exemplified by Chain-of-Thought techniques, remains a critical consideration. Encouraging LLMs to draw logical conclusions and generate explainable output is a promising avenue for improvement. Moreover, the exploration of interactive prompt design, resembling multi-turn QA interactions, holds potential for academia, enabling LLMs to iteratively refine and provide feedback on extracted data. In the ever-evolving landscape of information extraction with LLMs, these considerations are pivotal for unlocking new horizons and advancing the field.
Conclusion:
The adoption of Large Language Models (LLMs) in information extraction (IE) represents a significant shift in the field of Natural Language Processing (NLP). Their ability to generate structured information efficiently has the potential to revolutionize various industries that rely on NLP applications, such as knowledge graphs and question-answering systems. However, challenges persist in certain IE tasks, requiring continued research and development. As LLMs continue to evolve and improve, they are likely to play a crucial role in shaping the future of NLP-based solutions, offering businesses new opportunities for advanced data processing and knowledge extraction.