
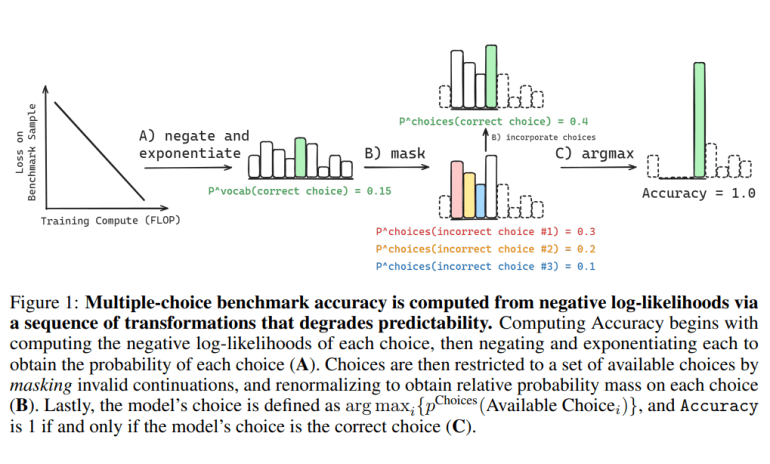
- Understanding how frontier AI models perform at scale is crucial for strategic decision-making.
- Despite scaling laws, predicting performance on tasks becomes challenging as systems grow.
- Conventional metrics may not adequately capture performance shifts with scale.
- Research explores beyond multiple-choice benchmarks to grasp broader implications.
- Challenges exist in predicting benchmark performance using traditional metrics.
- Efforts reveal the feasibility of evaluating common metrics directly from raw model outputs.
- Nuanced understanding of probability mass dynamics among incorrect choices is crucial.
- Per-sample scores from diverse model cohorts are essential for evaluating AI capabilities accurately.
- Accurate prediction of performance in multiple-choice tests requires nuanced understanding of shifting probabilities.
- Interplay between probabilities of correct and incorrect responses is vital in scaling predictions.
Main AI News:
Unraveling the intricacies behind the predictive behavior of leading AI systems such as GPT-4, Claude, and Gemini is pivotal for gauging their potential impact and guiding strategic decisions surrounding their advancement and deployment. Despite the well-documented correlation between parameters, data, computational resources, and pretraining loss as dictated by scaling laws, accurately foreseeing the performance of these systems across various tasks upon scaling remains a formidable challenge. Notably, conventional wisdom often falters when it comes to predicting the performance shifts of these systems on standard NLP benchmarks as they undergo scale augmentation. Several scholarly inquiries posit that the unpredictability may stem from the selection of metrics and the inherent lack of granularity in assessment methodologies.
This discourse unfolds along two primary trajectories. Firstly, the exploration delves into the realm of “Beyond Multiple Choice Benchmarks,” shedding light on assessments predominantly reliant on loglikelihood-based multiple-choice formats. While such a focus holds merit owing to the ubiquity and practicality of such benchmarks, its narrow scope may hinder a comprehensive understanding of the broader implications. Secondly, the narrative navigates through “Predicting Benchmark Performance A Priori,” elucidating the challenges in forecasting multiple-choice benchmark performance utilizing conventional metrics such as Accuracy and Brier Score. However, these analyses predicate upon access to comprehensive score datasets across diverse model cohorts spanning a spectrum of pretraining FLOPs, overlooking the potential insights gleaned from retrospective validation.
Collaborative efforts spearheaded by esteemed researchers from institutions including the University of Cambridge, Stanford CS, EleutherAI, and MILA have demonstrated the feasibility of evaluating common multiple-choice metrics—such as Accuracy, Brier Score, and Probability Correct—directly from raw model outputs. This feat is accomplished through a systematic series of transformations aimed at gradually attenuating the statistical correlations between these metrics and the underlying scaling parameters. The crux lies in the realization that these metrics hinge upon a direct juxtaposition between the correct output and a finite subset of predefined incorrect outputs. Hence, accurately prognosticating downstream performance necessitates a nuanced comprehension of the dynamic redistribution of probability mass among specific incorrect alternatives.
Pioneering investigations into the flux of probability mass across erroneous choices vis-à-vis escalating computational resources serve as a cornerstone in deciphering the erratic nature of individual downstream metrics, juxtaposed with the relative consistency exhibited by pretraining loss scaling laws, untethered from the constraints of specific incorrect choices. Crafting evaluation frameworks adept at delineating the trajectory of advanced AI capabilities mandates a profound grasp of the determinants influencing downstream performance. Furthermore, elucidating how the downstream competencies in designated tasks evolve across different model lineages necessitates the derivation of per-sample scores from diverse model cohorts across assorted multiple-choice NLP benchmarks.
Accurately prognosticating performance in multiple-choice question-answering assessments hinges upon discerning the nuanced variations in the probabilities associated with selecting the correct versus incorrect responses as scaling unfolds. For metrics like Accuracy, the ability to make such predictions mandates a granular understanding of the shifting probabilities associated with both correct and incorrect responses, on a question-by-question basis. Simply gauging the average likelihood of selecting incorrect responses across an array of questions fails to capture the nuanced probabilities inherent to each individual query. Consequently, meticulous scrutiny of the interplay between the probabilities of selecting correct and incorrect responses as computational resources expand emerges as a linchpin in prognosticating performance with precision.
Conclusion:
The study underscores the complexity of predicting the performance trajectory of cutting-edge AI models as they scale up. Businesses invested in AI development and deployment must navigate these intricacies, ensuring robust evaluation methodologies and a nuanced understanding of scaling dynamics to effectively harness the potential of advanced AI technologies in the market landscape.