
TL;DR:
- GPT-4 is a remarkable generative AI technology, but it faces challenges with factual accuracy in its generated content.
- FACTOOL is a cutting-edge framework developed by leading researchers to identify and rectify factual errors in texts produced by large language models (LLMs).
- The framework employs diverse resources and critical thinking skills in LLMs to comprehensively evaluate factuality without explicit claims and evidence.
- FACTOOL offers a unified and adaptable approach, successfully addressing factuality identification across various domains and tasks.
- GPT-4 emerges as the top performer in factuality, surpassing contemporary chatbots in different scenarios.
- This breakthrough in factuality detection enhances trust and reliability in LLM outputs, making them more viable for critical industries.
- However, there are still challenges for chatbots to achieve optimal factuality in complex tasks like scientific literature reviews and mathematical problem-solving.
Main AI News:
In the rapidly evolving world of artificial intelligence, the advent of GPT-4 has brought forth a remarkable example of generative AI technology. By seamlessly integrating various natural language processing tasks into a cohesive sequence-generating system, GPT-4 has unlocked new dimensions of efficiency and interactivity. This unified architecture empowers users to accomplish diverse activities using a simple natural language interface, ranging from code generation and mathematical problem-solving to the creation of scientific publications. However, with this great power comes a unique set of challenges.
Large language models (LLMs), such as GPT-4, are adept at producing text that appears convincing. Nevertheless, they occasionally fall short in terms of accuracy and precision in their generated content. As a result, certain industries with high stakes, such as healthcare, finance, and law, approach generative AI with caution due to the potential risks posed by factual errors. Recognizing this limitation, the community has been actively seeking methods to methodically identify and rectify such mistakes.
Enter FACTOOL, a pioneering task- and domain-agnostic framework meticulously developed by a consortium of distinguished researchers from leading institutions. Hailing from Shanghai Jiao Tong University, Carnegie Mellon University, City University of Hong Kong, New York University, Meta AI, The Hong Kong University of Science and Technology, and Shanghai Artificial Intelligence Laboratory, this groundbreaking solution seeks to address the challenge of factuality detection in documents generated by LLMs.
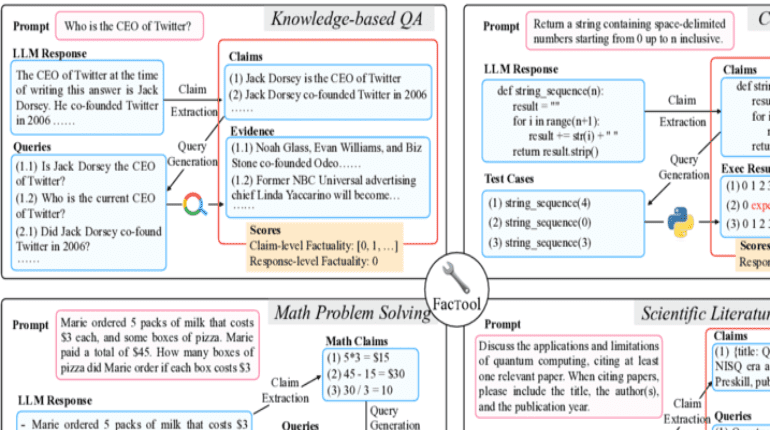
The hallmark of FACTOOL lies in its extraordinary adaptability, owing to the vast array of activities and domains that LLMs handle. It goes beyond the conventional definitions of factuality detection, which typically revolve around assessing the accuracy of claims or determining if a claim is supported by evidence. Instead, FACTOOL confronts the more intricate task of evaluating the factuality of long-form text generations, particularly in scenarios where explicit claims and evidence are absent.
To accomplish this feat, FACTOOL harnesses a diverse set of resources, including Google Search, Google Scholar, code interpreters, Python, and even other LLMs. Leveraging critical thinking skills inherent in LLMs, the framework thoroughly evaluates the factual accuracy of generated content based on the available data. It creates a comprehensive benchmark and carries out experiments across four distinct tasks: knowledge-based quality assurance, code creation, mathematical problem-solving, and writing scientific literature reviews.
The researchers’ efforts lead to an impressive expansion of factuality identification, ushering in a new era of comprehensive scrutiny for the latest generative AI models. By seamlessly integrating “tool use” and “factuality detection,” FACTOOL provides a unified and versatile approach that transcends various domains and activities. Their rigorous analysis indicates that GPT-4 emerges as the reigning champion in terms of factuality across a wide range of scenarios, outperforming contemporary chatbots.
While carefully honed chatbots like Vicuna-13B demonstrate commendable factuality in knowledge-based quality assurance tests, they grapple with more complex tasks like crafting scientific literature reviews and solving intricate mathematical problems.
Conclusion:
The introduction of FACTOOL marks a significant leap in factuality detection for large language models. As AI continues to shape various markets, this advancement ensures that LLMs can be deployed more confidently in industries with high risks, such as healthcare, finance, and law. The enhanced accuracy and precision provided by FACTOOL enable LLMs to unlock their full potential, revolutionizing the way businesses interact with generative AI technology. This will undoubtedly open up new opportunities and applications across the market, paving the way for responsible and effective AI utilization.