
TL;DR:
- FANToM: A benchmark challenging machine Theory of Mind in conversational AI.
- Passive narratives fall short in assessing ToM capabilities.
- Diverse questions designed to test LLMs’ reasoning skills.
- State-of-the-art LLMs struggle with ToM questions, even with advanced techniques.
- Researchers introduce FANToM, a robust ToM benchmark for LLMs.
- FANToM evaluates LLMs through binary responses and character knowledge listing.
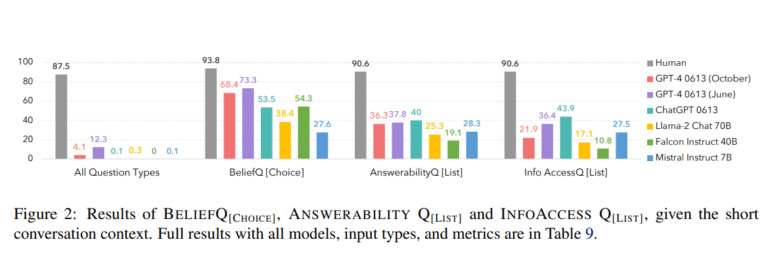
- Human performance was assessed with 11 student volunteers.
- FANToM includes 10,000 questions in multiparty conversations, emphasizing information asymmetry.
- The benchmark measures models’ ability to track beliefs and detect illusory ToM.
- Current LLMs consistently underperform compared to humans, despite improvements.
- Challenges in developing models with coherent Theory of Mind reasoning.
- The need for interaction-centric standards in real-world scenarios.
- FANToM is publicly available for further research, encouraging progress in ToM understanding.
Main AI News:
In the realm of conversational AI, the evaluation of the Theory of Mind (ToM) through question-answering has evolved into an indispensable benchmark. Nevertheless, the assessment of ToM capabilities in passive narratives requires refinement. To overcome this challenge, a set of diverse questions has been meticulously crafted to demand the same level of reasoning skills. These probing inquiries have, in turn, laid bare the limited ToM prowess of Language Model Models (LLMs). Even with sophisticated chain-of-thought reasoning or fine-tuning, state-of-the-art LLMs still find themselves in need of assistance when confronted with these questions, consistently falling short of human performance standards.
Enter FANToM, a groundbreaking benchmark introduced by a consortium of researchers hailing from various esteemed universities. FANToM serves as the litmus test for assessing ToM in LLMs, specifically in the context of conversational question answering. This benchmark is unique in that it incorporates both psychological insights and empirical data into the evaluation of LLMs. Astonishingly, FANToM proves to be an arduous challenge even for the most advanced LLMs, which, despite their cutting-edge reasoning capabilities and fine-tuning, still trail behind humans in their performance.
The methodology of FANToM involves evaluating LLMs by soliciting binary responses to questions concerning characters’ knowledge and the listing of characters possessing specific information. To gauge human performance, the benchmark enlisted the participation of 11 student volunteers.
FANToM, an innovative English benchmark, has been meticulously designed to appraise the machine’s ToM in the context of conversational interactions, with a particular emphasis on social dynamics. It comprises a vast pool of 10,000 questions embedded within multiparty conversations, deliberately highlighting information asymmetry and distinct mental states exhibited by the characters. The ultimate objective is to assess the ability of models to trace beliefs in dialogues, thereby scrutinizing their capacity to comprehend the mental states of others and discerning instances of illusory ToM.
The testing ground of FANToM lies in question-answering within conversational settings, where information asymmetry prevails. This comprehensive benchmark features 10,000 questions grounded in multiparty conversations, where characters grapple with distinct mental states resulting from inaccessible information. FANToM, in essence, evaluates the capability of LLMs to navigate the intricacies of belief tracking during discussions and pinpoint instances of illusory ToM. Despite resorting to chain-of-thought reasoning or fine-tuning, existing LLMs consistently lag behind humans, as corroborated by the evaluation results.
The evaluation findings of FANToM starkly highlight that, even with the application of chain-of-thought reasoning or fine-tuning, current LLMs continue to underperform in comparison to humans. Certain instances of LLM ToM reasoning within the FANToM framework are labeled as illusory, underscoring their inability to grasp distinct character perspectives. While the utilization of zero-shot chain-of-thought logic or fine-tuning does lead to incremental improvements in LLM performance, substantial disparities persist when measured against human standards. These findings serve as a poignant reminder of the formidable challenges inherent in developing models capable of cohesive Theory of Mind reasoning, emphasizing the formidable task of achieving human-level comprehension in LLMs.
FANToM stands as a valuable benchmark for the evaluation of ToM in LLMs during conversational interactions. It shines a spotlight on the pressing need for interaction-centric standards that align more closely with real-world usage scenarios. The benchmark’s outcomes conclusively demonstrate that current LLMs consistently fall short of human performance, even when employing advanced techniques. Additionally, it underscores the pivotal issue of internal consistency within neural models and suggests various approaches to tackle this challenge. FANToM places a strong emphasis on the differentiation between accessible and inaccessible information in the realm of ToM reasoning.
As we look to the future, research endeavors are poised to explore avenues such as grounding ToM reasoning in pragmatics, leveraging visual information, and harnessing belief graphs. Evaluations are expected to encompass a broader spectrum of conversation scenarios, extending beyond mere small talk on specific topics, with the integration of multi-modal aspects like visual information. Addressing the thorny issue of internal consistency within neural models remains a paramount concern. To facilitate further research in the realm of ToM understanding in LLMs, FANToM is now publicly available. This move heralds a new era of progress in the field, one that encourages the incorporation of relationship variables for more dynamic and sophisticated social reasoning.
Conclusion:
FANToM highlights the substantial gap between current Language Model Models (LLMs) and human performance in Theory of Mind reasoning. This benchmark underscores the need for more interaction-oriented standards in the field of conversational AI. The challenges revealed in FANToM point to opportunities for further research and innovation, particularly in addressing the internal consistency issue within neural models and advancing ToM understanding in LLMs. This, in turn, signals the potential for growth and development in the market of conversational AI solutions, as businesses seek more sophisticated and human-like conversational AI models.