
TL;DR:
- FineMoGen, developed by S-Lab and Sense Time Research, redefines motion generation in digital environments.
- Combining diffusion models with Spatio-Temporal Mixture Attention (SAMI), it excels in generating lifelike human actions.
- FineMoGen breaks down complex motion instructions into spatial and temporal components, ensuring realism.
- The inclusion of a sparsely activated Mixture-of-Experts (MoE) enhances its motion generation capabilities.
- Rigorous testing proves FineMoGen’s superiority over existing methods in motion synthesis.
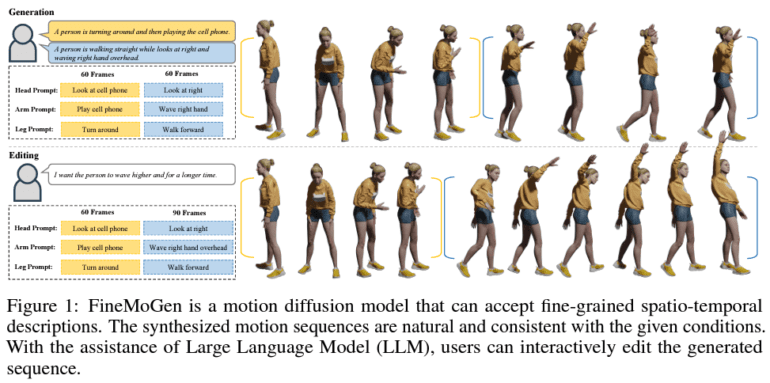
- It introduces zero-shot motion editing, allowing users to modify generated motions with new instructions.
- The creation of a vast dataset with fine-grained spatiotemporal text annotations opens new possibilities for research.
- FineMoGen’s impact spans industries like animation, virtual reality, and virtual training.
Main AI News:
In the ever-evolving landscape of computer vision and digital animation, the quest for creating lifelike human actions within virtual environments has long been a challenge. Enter FineMoGen, an innovative framework developed by the esteemed S-Lab at Nanyang Technological University in collaboration with Sense Time Research. FineMoGen not only tackles this challenge head-on but also raises the bar by introducing a novel approach that seamlessly integrates the realms of diffusion models and transformer architecture.
Motion generation, a field crucial to industries spanning from animation to virtual reality, has struggled to capture the intricacies of human movements. Existing methods, while advancing the field, have often fallen short in faithfully reproducing the nuanced details of spatial and temporal dynamics in human actions. FineMoGen, with its groundbreaking Spatio-Temporal Mixture Attention (SAMI) mechanism, takes a giant leap forward in this domain.
At its core, FineMoGen redefines the art of generating human motion by leveraging diffusion-based models and SAMI architecture. SAMI, an ingenious transformer approach, empowers FineMoGen to decode fine-grained textual instructions and transform them into lifelike motion sequences. The result? A model that not only comprehends the intricacies of human movement but also translates them into a vivid, spatial-temporal canvas.
One of FineMoGen’s key strengths lies in its ability to dissect complex motion instructions into discrete spatial components and temporal segments. This meticulous approach ensures that each movement aligns precisely with user-defined parameters, delivering unparalleled realism in motion synthesis. Additionally, FineMoGen incorporates a sparsely activated Mixture-of-Experts (MoE) within its architecture, adding yet another layer of sophistication to its motion generation capabilities.
The performance of FineMoGen is nothing short of remarkable. Rigorously tested against industry benchmarks, it consistently surpasses existing state-of-the-art methods in motion generation. Its proficiency in generating natural, detailed human motions based on fine-grained textual descriptions sets it apart. What’s more, FineMoGen introduces a groundbreaking feature – zero-shot motion editing. Users can effortlessly modify generated motions with new instructions, a capability previously unavailable in the realm of motion synthesis.
Beyond revolutionizing motion generation, this research effort has laid the foundation for future advancements. It includes the creation of an expansive dataset, enriched with fine-grained spatiotemporal text annotations, which promises to drive further innovation in the field. With FineMoGen leading the way, the future of realistic and detailed human motion generation in applications ranging from entertainment to virtual training looks brighter than ever.
Conclusion:
FineMoGen’s arrival signifies a significant leap forward in the market for realistic digital motion synthesis. Its ability to generate fine-grained, lifelike human motions and introduce zero-shot editing capabilities places it at the forefront of the industry, promising to shape the future of animation, virtual reality, and interactive media. Moreover, the creation of a robust dataset enriches resources for further innovation, ensuring a bright future for detailed human motion generation across various applications.