
- FineWeb, a meticulously crafted 15T Token open-source dataset, undergoes thorough processing to ensure high quality and suitability for language model training.
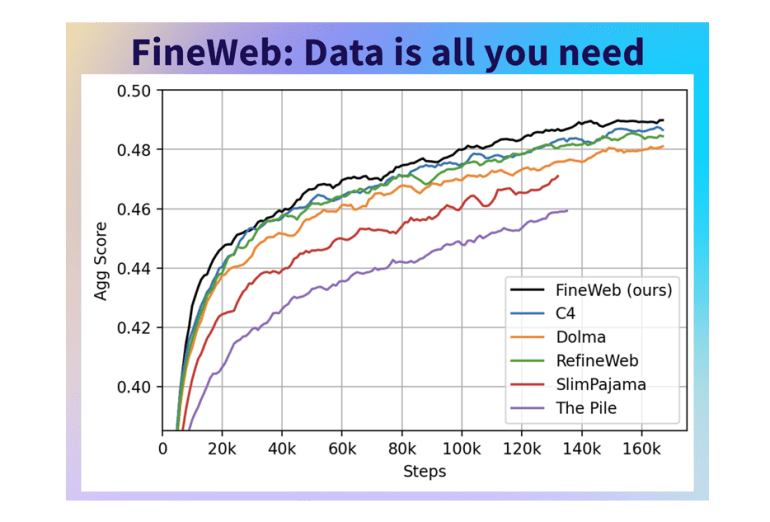
- Through innovative curation and filtering techniques, FineWeb outperforms established datasets like C4, Dolma v1.6, The Pile, and SlimPajama in various benchmark tasks.
- Transparency and reproducibility are central to FineWeb’s development, with the dataset and processing pipeline code released under the ODC-By 1.0 license.
- FineWeb’s journey from conception to release involves meticulous craftsmanship and rigorous testing, with each stage of the filtering process contributing to the dataset’s integrity.
- With its extensive collection of curated data and commitment to openness and collaboration, FineWeb holds the potential to drive groundbreaking research and innovation in language models.
Main AI News:
In the realm of language model advancement, meticulous attention to detail is paramount. FineWeb exemplifies this ethos through its rigorous processing pipeline, facilitated by the datatrove library. This meticulous approach ensures that the dataset undergoes thorough cleaning and deduplication, elevating its quality and efficacy for language model training and assessment.
FineWeb distinguishes itself through unparalleled performance metrics. Employing innovative curation techniques and advanced filtering methodologies, FineWeb surpasses established datasets like C4, Dolma v1.6, The Pile, and SlimPajama across various benchmark tasks. Models trained on FineWeb consistently exhibit superior performance, underscoring its potential as an indispensable asset for natural language understanding research.
Central to FineWeb’s ethos is transparency and reproducibility. The dataset, coupled with the code for its processing pipeline, is made available under the ODC-By 1.0 license, empowering researchers to replicate and expand upon its discoveries effortlessly. FineWeb upholds its commitment to transparency through comprehensive ablations and benchmarks, validating its efficacy against established datasets and affirming its reliability and relevance in language model research.
The journey of FineWeb from conceptualization to fruition is a testament to meticulous craftsmanship and stringent testing. Each stage of the filtering process, from URL filtering to language detection and quality assessment, contributes to the dataset’s integrity and comprehensiveness. Leveraging advanced MinHash techniques, FineWeb meticulously deduplicates each CommonCrawl dump individually, further enhancing its quality and usability.
As the research community delves deeper into the vast potential of FineWeb, it emerges as a cornerstone for advancing natural language processing. With its extensive collection of curated data and unwavering commitment to openness and collaboration, FineWeb stands poised to catalyze groundbreaking research and foster innovation in the realm of language models.
Conclusion:
The emergence of FineWeb signifies a significant advancement in language model training and research. Its superior performance, coupled with transparency and extensive data curation, positions FineWeb as a catalyst for innovation in the language model market. Businesses and researchers alike stand to benefit from its comprehensive dataset and potential for driving groundbreaking advancements in natural language processing.