
TL;DR:
- Flash-Decoding introduces a groundbreaking AI approach based on FlashAttention.
- It accelerates LLM inference up to 8 times, optimizing operational costs.
- Large Language Models like ChatGPT and Llama benefit from this innovation.
- High operational costs of LLMs pose a challenge.
- Flash-Decoding’s novel parallelization approach enhances GPU utilization.
- It reduces GPU memory requirements and improves decoding speeds.
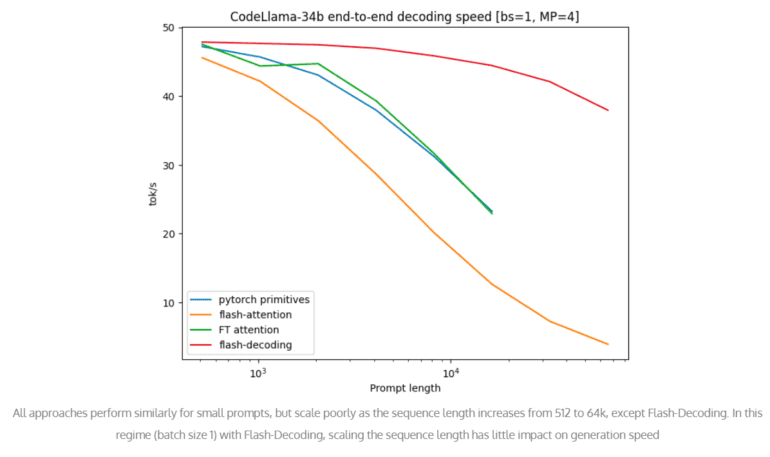
- Benchmark tests on the CodeLLaMa-34b model showcase an 8x speed increase.
- Micro-benchmarks confirm consistent performance even with longer sequences.
Main AI News:
In the realm of Artificial Intelligence, a groundbreaking development has emerged, promising to revolutionize the efficiency and scalability of Large Language Models (LLMs). This innovation, known as Flash-Decoding, harnesses the power of FlashAttention, presenting a novel approach that has the potential to make long-context LLM inference up to 8 times faster. In a world where LLMs like ChatGPT and Llama have become pivotal players in various applications, from text generation to code completion, the need for optimization is paramount.
The formidable capabilities of LLMs come at a cost. With the average price tag of generating a single response amounting to $0.01, the expenses associated with deploying these models to serve a global audience with multiple daily interactions are staggering. These operational costs, especially in intricate tasks like code auto-completion, can escalate exponentially. It is in this context that the importance of optimizing the decoding process, particularly the attention operation, becomes evident.
LLM inference, often referred to as decoding, involves a step-by-step generation of tokens, with the attention operation being a critical factor in determining the overall generation time. Despite notable advancements like FlashAttention v2 and FasterTransformer, which have improved the training process, challenges persist during the inference phase. A significant hurdle is encountered when dealing with longer contexts, as the attention operation’s scalability becomes a bottleneck. As LLMs are increasingly tasked with handling more extensive documents, conversations, and codebases, the attention operation can consume a substantial amount of inference time, hampering the model’s overall efficiency.
Enter Flash-Decoding, a game-changing technique that builds upon prior methodologies to address these challenges head-on. The core innovation of Flash-Decoding revolves around the parallelization of keys and values, strategically partitioning them into smaller fragments. This approach enables highly efficient utilization of GPU resources, even with smaller batch sizes and extended contexts. Notably, Flash-Decoding dramatically reduces GPU memory requirements through parallelized attention computations and the log-sum-exp function, streamlining computation across the entire model architecture.
To assess the effectiveness of Flash-Decoding, comprehensive benchmark tests were conducted on the renowned CodeLLaMa-34b model, celebrated for its robust architecture and advanced capabilities. The results were nothing short of impressive, showcasing an astonishing 8-fold increase in decoding speeds for longer sequences compared to existing approaches. Furthermore, micro-benchmarks were performed on the scaled multi-head attention, demonstrating consistent performance even with sequence lengths scaled up to 64k. This exceptional performance has ushered in a new era of efficiency and scalability for LLMs, marking a significant milestone in large language model inference technologies.
Conclusion:
Flash-Decoding represents a transformative development in the AI market. By addressing the efficiency challenges of Large Language Models, it offers a cost-effective solution that not only enhances the capabilities of these models but also opens up new possibilities for businesses to leverage natural language processing technologies more efficiently. As organizations seek to deploy LLMs across a wide range of applications, Flash-Decoding’s ability to make them up to 8 times faster holds immense promise for reducing operational costs and increasing productivity, making it a game-changer in the AI landscape.