
- FlashSpeech introduces an efficient zero-shot speech synthesis system.
- It leverages the latent consistency model (LCM) and adversarial consistency training for accelerated inference speed.
- The prosody generator module enhances prosodic diversity while maintaining stability.
- FlashSpeech surpasses benchmarks in audio quality and speaker similarity, achieving speeds approximately 20 times faster than comparable systems.
Main AI News:
The landscape of speech synthesis has witnessed a monumental shift in recent times, courtesy of the advent of large-scale generative models. These advancements have propelled zero-shot speech synthesis systems, spanning text-to-speech (TTS), voice conversion (VC), and editing, into new realms of capability by seamlessly integrating unseen speaker attributes from a reference audio snippet during inference, without necessitating additional training data.
However, the evolution of such systems, primarily reliant on language and diffusion-style models, has been hampered by prolonged computational durations and associated costs. Addressing this critical challenge head-on, a pioneering team of researchers has introduced FlashSpeech, a paradigm-shifting innovation in efficient zero-shot speech synthesis. This groundbreaking methodology builds upon recent strides in generative modeling, notably the latent consistency model (LCM), which offers a promising avenue for accelerating inference speed.
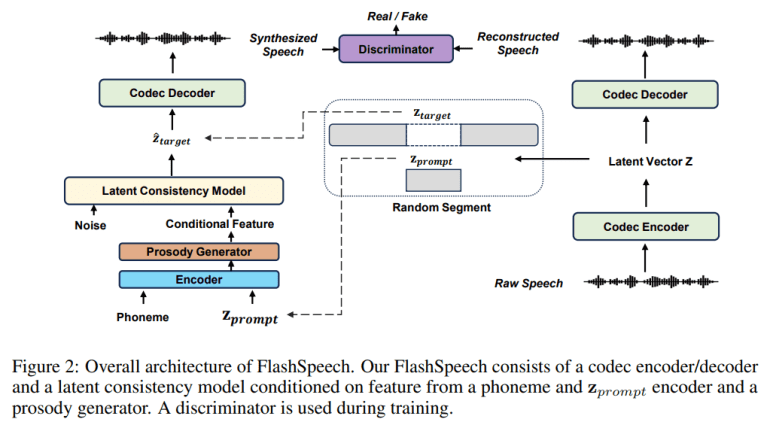
Central to FlashSpeech is its utilization of the LCM in conjunction with a neural audio codec’s encoder to transform speech waveforms into latent vectors during training. Crucially, the researchers employ adversarial consistency training, a novel fusion of consistency and adversarial training leveraging pre-trained speech-language models as discriminators, to ensure model efficiency.
A cornerstone of FlashSpeech lies in its prosody generator module, designed to enrich prosodic diversity while maintaining stability. By conditioning the LCM on prior vectors derived from a phoneme encoder, a prompt encoder, and the prosody generator, FlashSpeech achieves heightened expressiveness and prosody in the synthesized speech.
In terms of performance, FlashSpeech not only outstrips robust benchmarks in audio fidelity but also rivals them in speaker similarity. Most notably, it achieves this feat at an astonishing speed, approximately 20 times faster than comparable systems, signaling a quantum leap in efficiency for zero-shot speech synthesis.
The advent of FlashSpeech heralds a significant advancement in the realm of zero-shot speech synthesis, surmounting the fundamental limitations of existing methodologies and harnessing cutting-edge generative modeling innovations. With its unparalleled generation speed and superior performance, FlashSpeech emerges as a compelling solution for real-world applications necessitating swift, high-quality speech synthesis.
With its remarkable efficiency and efficacy, FlashSpeech holds tremendous promise across diverse domains, from virtual assistants to audio content creation and accessibility tools. As the field continues to progress, FlashSpeech stands poised to establish a new benchmark for efficient and effective zero-shot speech synthesis systems.
Conclusion:
The emergence of FlashSpeech represents a significant breakthrough in the market for zero-shot speech synthesis systems. Its efficient generation speed and superior performance offer compelling advantages for various applications, positioning it as a leading solution in the evolving landscape of speech technology. Businesses and industries reliant on rapid, high-quality speech synthesis stand to benefit significantly from the implementation of FlashSpeech.