
TL;DR:
- Language models like GPT and LLaMA have become vital for natural language processing.
- Creating these models from scratch is costly and energy-intensive.
- The fusion of pre-trained models, known as FuseLLM, offers a cost-effective alternative.
- Knowledge fusion involves merging diverse models to maximize strengths and minimize costs.
- Traditional methods like ensemble strategies and weight merging have limitations.
- Knowledge fusion leverages generative distributions, aligning and fusing them.
- Implementation involves meticulous tokenization alignment and significance evaluation.
- Rigorous testing shows that FuseLLM outperforms individual models in various tasks.
Main AI News:
The emergence of colossal language models, exemplified by the likes of GPT and LLaMA, has undeniably marked a transformative epoch in the realm of natural language processing. These monumental models have swiftly become indispensable assets for an array of linguistic tasks. However, the genesis of such models from the ground up entails exorbitant expenses, monumental computational resources, and substantial energy consumption. Consequently, the pursuit of cost-effective alternatives has gained momentum. One such innovative paradigm shift revolves around the amalgamation of pre-existing, pre-trained large language models into a more formidable and efficient composite entity. This strategic maneuver not only promises a diminution in resource outlay but also synergizes the myriad strengths harbored within diverse models.
Yet, the amalgamation of multiple large language models is no facile endeavor, primarily owing to the intrinsic architectural disparities among them. A mere amalgamation of their respective weightings proves unfeasible, necessitating a more nuanced approach. The crux of knowledge fusion within large language models is to conjoin these linguistic leviathans, birthing an entirely new, potent entity that capitalizes on the strengths while diminishing the associated costs. This fusion methodology holds boundless potential for enhancing performance across a spectrum of linguistic tasks, providing an adaptable, versatile tool tailored for multifarious applications.
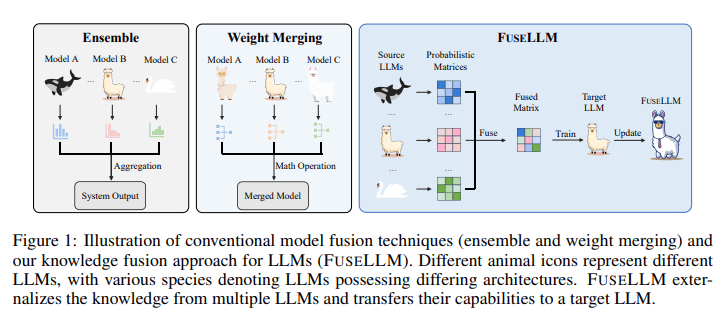
Conventional methodologies for integrating language models typically involve ensemble strategies and weight consolidation. However, the practical challenges wrought by the expansive memory and time requisites of large language models often hinder the efficacy of ensemble methods. Meanwhile, weight consolidation frequently falls short of delivering optimal results, especially when applied to models with profound disparities in parameter spaces. These intrinsic limitations necessitate an innovative approach to effectively coalesce the capabilities of disparate large language models.
Enter the groundbreaking concept of knowledge fusion for large language models, introduced by researchers from Sun Yat-sen University and Tencent AI Lab in response to the aforementioned challenges. This ingenious method capitalizes on the generative distributions of source large language models, externalizing their reservoirs of knowledge and strengths, subsequently transferring them to a target large language model via lightweight, ongoing training. At the heart of this pioneering approach lies the intricate task of aligning and fusing the probabilistic distributions generated by the source large language models. This intricate process entails the development of novel strategies for aligning tokenizations and the exploration of innovative methods for harmonizing probability distributions. A paramount emphasis is placed on the minimization of divergence between the probabilistic distributions of the target and source large language models.
The implementation of this methodology is an intricate endeavor, necessitating a meticulous alignment of tokenizations across diverse large language models. This meticulous endeavor is imperative for the effective fusion of knowledge, ensuring the accurate mapping of probabilistic distribution matrices. The fusion process entails the evaluation of the quality of disparate large language models and the assignment of varying degrees of significance to their respective distribution matrices based on predictive excellence. This nuanced approach empowers the fused model to harness collective knowledge while preserving the distinctive strengths inherent to each source large language model.
To assess the efficacy of FuseLLM, rigorous testing was conducted, utilizing three popular open-source large language models with distinct architectures: Llama-2, MPT, and OpenLLaMA. The evaluation encompassed an array of benchmarks, spanning reasoning, commonsense, and code generation tasks. The results proved nothing short of remarkable, with the fused model consistently outperforming each source large language model and the baseline in the majority of tasks. This comprehensive study has unequivocally demonstrated substantial enhancements across various capabilities, thereby underscoring the profound effectiveness of FuseLLM in amalgamating the collective strengths of individual large language models.
Conclusion:
The introduction of FuseLLM represents a groundbreaking development in the field of language models. By efficiently fusing diverse pre-trained models, FuseLLM not only reduces resource expenditure but also enhances performance across a range of tasks. This innovation is poised to disrupt the market by providing cost-effective solutions that leverage the collective knowledge and strengths of existing models, making it a valuable asset for businesses and industries relying on natural language processing.