
TL;DR:
- Fuyu-Heavy, the latest multimodal model from Adept AI, ranks as the world’s third-most-capable, outperforming Gemini Pro.
- It successfully balances language and image modeling tasks, demonstrating remarkable performance across diverse benchmarks.
- The model’s development faced challenges due to its scale, involving training on both textual and visual data, and managing image data stress on systems.
- Innovative dataset methods and rigorous quality assurance measures were employed to address these challenges.
- Fuyu-Heavy excels in conversational AI, competing effectively with larger counterparts on popular chat evaluation platforms.
- Adept AI aims to enhance the base-model capabilities for practical agent applications, focusing on reward modeling, self-play, and advanced search techniques.
- The model’s potential to seamlessly integrate text and image processing tasks promises significant applications across various domains.
Main AI News:
In the ever-evolving landscape of Artificial Intelligence (AI), the demand for versatile Machine Learning (ML) models has surged, giving rise to the prominence of multimodal models. These cutting-edge models, which seamlessly fuse text and image data, have become integral to a wide array of AI applications, mirroring the complexity of human cognition.
Enter Fuyu-Heavy, the latest multimodal marvel from Adept AI. Positioned as the world’s third-most-capable multimodal model, it stands tall, outpacing Gemini Pro in Multimodal Language Understanding (MMLU) and Multimodal Model Understanding (MOU), trailing only behind the formidable GPT4-V and Gemini Ultra. Remarkably, Fuyu-Heavy achieves this feat while maintaining a relatively compact size compared to its counterparts, showcasing remarkable performance across diverse benchmarks.
A delicate balance between language and image modeling tasks was essential in crafting Fuyu-Heavy. Adept AI’s researchers undertook specialized methodologies to scale up its performance without compromising its efficiency. The model’s formulation presented formidable challenges, given its sheer scale and the intricate process of training a novel architecture on both textual and visual data.
Notably, the integration of image data into the training regimen placed significant demands on computational resources, necessitating meticulous management of data influx, memory utilization, and cloud storage bandwidth. Additionally, the quest for high-quality image pre-training data posed its own set of challenges. In response, researchers devised innovative dataset techniques, leveraging existing resources and synthetic data generation to bolster the model’s image-processing capabilities.
Handling coordinate systems during training and inference, along with diverse image formats, added complexity to the project. Adept AI researchers left no stone unturned, applying rigorous quality assurance measures and meticulous attention to detail to conquer these challenges.
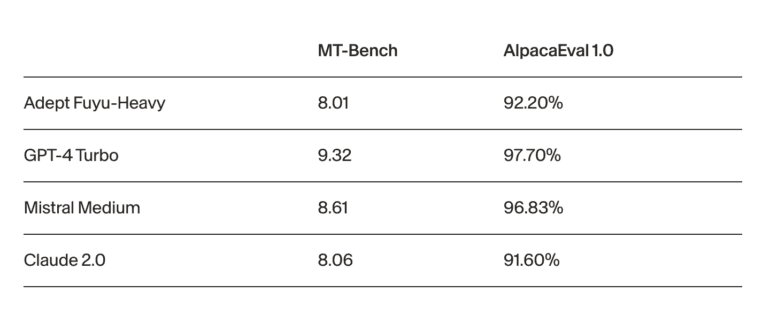
The results are nothing short of spectacular. Fuyu-Heavy has been rigorously tested across various benchmarks, consistently surpassing the performance of larger models within its computing class. Notably, it holds its own in the realm of conversational AI, competing favorably with larger counterparts like Claude 2.0 on popular chat evaluation platforms such as MT-Bench and AlpacaEval 1.0.
Looking ahead, Adept AI is committed to enhancing the base-model capabilities of Fuyu-Heavy. The research team is actively exploring avenues to transform these models into practical agents through reward modeling, self-play, and advanced inference-time search techniques. Their focus extends to creating reliable products that leverage Fuyu-Heavy’s unparalleled ability to seamlessly integrate text and image processing tasks, promising substantial potential across diverse domains.
Conclusion:
Fuyu-Heavy’s emergence as a powerful multimodal model signifies a significant advancement in AI capabilities. Its ability to efficiently handle text and image data while maintaining a smaller size has the potential to reshape various markets, especially in conversational AI and image processing, ushering in a new era of AI-driven innovation and applications.