
- Galileo introduces Luna, an advanced evaluation foundation model targeting hallucinations in language models.
- Luna is engineered to enhance accuracy, reduce costs, and speed up response times in detecting errors in large language models.
- The model uses a DeBERTa-large encoder, optimized for both accuracy and speed, making it suitable for diverse industrial applications.
- Luna offers significant cost reductions and performance improvements over existing models like GPT-3.5.
- Customizable features of Luna allow for rapid adaptation to specific industry requirements, enhancing its versatility across various fields.
Main AI News:
The introduction of the Galileo Luna marks a pivotal step forward in evaluating language models. This model is meticulously engineered to tackle the widespread problem of hallucinations within large language models (LLMs). These hallucinations—instances where models produce unanchored data—present major obstacles for applying language models in various industry sectors. The Luna model, a specialized evaluation foundation model (EFM), guarantees elevated accuracy, swift response times, and economic efficiency in identifying and controlling these inaccuracies.
Addressing Hallucinations in LLMs
The advent of large language models has transformed the field of natural language processing due to their advanced text generation capabilities resembling human-like output. Yet, their propensity to generate erroneous data compromises their dependability, particularly in sectors like customer support, legal consulting, and healthcare research. Factors contributing to hallucinations include outdated databases, arbitrary response generation, flawed training datasets, and the assimilation of new information during refinement stages. To counteract these challenges, retrieval-augmented generation (RAG) mechanisms have been designed to merge pertinent external data into the LLM’s outputs. However, current techniques for detecting hallucinations often struggle to maintain a balance between accuracy, response time, and cost, limiting their application in real-time, extensive industry settings.
Luna: The Benchmark Evaluation Model
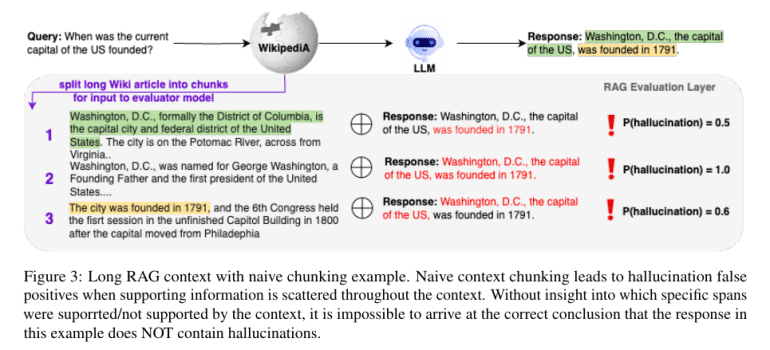
Galileo Technologies has unveiled Luna, a state-of-the-art DeBERTa-large encoder, optimized to pinpoint hallucinations within RAG frameworks. Distinguished by its precision, affordability, and rapid inference capabilities, Luna outshines prior models like GPT-3.5 in both efficacy and performance. Luna’s framework relies on a 440-million parameter DeBERTa-large model, honed with authentic RAG data. This structure is adept at generalizing across diverse industry landscapes and managing extensive-context RAG inputs, positioning it as a versatile tool for varied applications. Its training includes an innovative segmentation technique that processes extensive document contexts to diminish the occurrence of false positives in hallucination detection.
Top 5 Innovations in GenAI Assessments via Galileo Luna:
- Unmatched Accuracy in Evaluation: Luna achieves an 18% higher accuracy rate in detecting hallucinations within RAG systems compared to GPT-3.5, with this precision extending to various other assessment tasks, including prompt injections and PII identification.
- Extremely Cost-Effective Evaluation: Luna drastically lowers evaluation expenses by 97% relative to GPT-3.5, making it an economical choice for extensive implementations.
- Supreme Speed in Evaluation: Luna is 11 times faster than GPT-3.5, performing assessments in mere milliseconds to deliver a fluid and efficient user experience.
- Hallucination, Security, and Privacy Detection without Ground Truth: Luna negates the need for expensive, time-consuming ground truth testing sets by utilizing pre-established, evaluation-specific datasets, facilitating immediate and precise assessments.
- Designed for Tailored Adjustments: Luna can be rapidly adapted to specific sector requirements, providing highly accurate custom evaluation models promptly.
Efficacy and Economic Viability
Luna demonstrates superior performance in comprehensive benchmarks against other models, achieving a 97% reduction in costs and a 91% decrease in latency. These efficiencies are crucial for widespread deployment, emphasizing the importance of immediate response generation and cost control. The model processes up to 16,000 tokens within milliseconds, making it ideal for real-time operations such as customer interactions and automated chatbots. Luna’s compact architecture allows for local GPU deployment, maintaining data confidentiality and security, an essential benefit over external API-based solutions.
Versatility and Adaptability
Luna’s design promotes extensive adaptability, enabling modifications to suit distinct sector demands. For example, in the pharmaceutical sector, where inaccurate information can lead to severe consequences, Luna can be specifically adjusted to identify certain hallucination types with more than 95% precision. This adaptability ensures that the model can be tailored to various fields, increasing its practicality and impact. Luna supports a spectrum of assessment tasks beyond detecting hallucinations, including adherence to context, chunk usage, relevance of context, and security evaluations. Its multi-task training regimen enables it to conduct various assessments with a single input, providing comprehensive and accurate insights across different tasks.
Conclusion:
The launch of Galileo Luna represents a significant technological advancement in the field of language model evaluation. Its ability to accurately detect hallucinations while maintaining low costs and high efficiency positions it as a transformative tool for the industry. This model sets new benchmarks in evaluation accuracy and operational speed, likely influencing future developments in AI and machine learning technologies. By reducing the barriers to effective and efficient AI deployment, Luna not only enhances the reliability of language models but also broadens their applicability across critical sectors, potentially leading to increased adoption and innovation in AI-driven applications. This could drive further investment and focus on refining AI evaluation models, reshaping the market landscape and setting new standards for industry practices.