
TL;DR:
- Generative AI, exemplified by ChatGPT, is driving unprecedented demand for compute resources.
- Altman Solon predicts a surge in demand for data centers and networking infrastructure due to enterprise-level generative AI tools.
- Training and inference phases require substantial compute resources, with inference taking up the majority of workloads.
- Public clouds and core data centers will experience the most significant impact, necessitating regional capacity planning.
- Backbone and metro fiber networks will face increased demand, while access networks will see moderate impact.
- Future optimization may push inference to metro data centers and edge compute locations.
- On-premise hardware may be explored for local LLM running.
- Infrastructure providers should focus on adaptability to service this technology.
Main AI News:
The realm of generative AI has witnessed an explosive surge, revolutionizing the landscape of network infrastructure. As the final installment in the thought-provoking series, “Putting Generative AI to Work,” Altman Solon, the renowned global strategy consulting firm, delves into the profound impact of emerging enterprise generative AI solutions on the realms of compute, storage, and networking infrastructure.
At the forefront of this generative AI revolution stands none other than ChatGPT, the talkative and engaging app crafted by OpenAI. This ingenious creation captivated millions worldwide with its remarkably lifelike responses to a diverse array of queries. Powering ChatGPT is OpenAI’s awe-inspiring large language model (LLM), running on an extensive supercomputing infrastructure. Microsoft Azure, the esteemed cloud computing platform, has been a crucial partner in training the ChatGPT model, linking thousands of Nvidia graphics processing units (GPUs) while expertly managing cooling and power constraints.
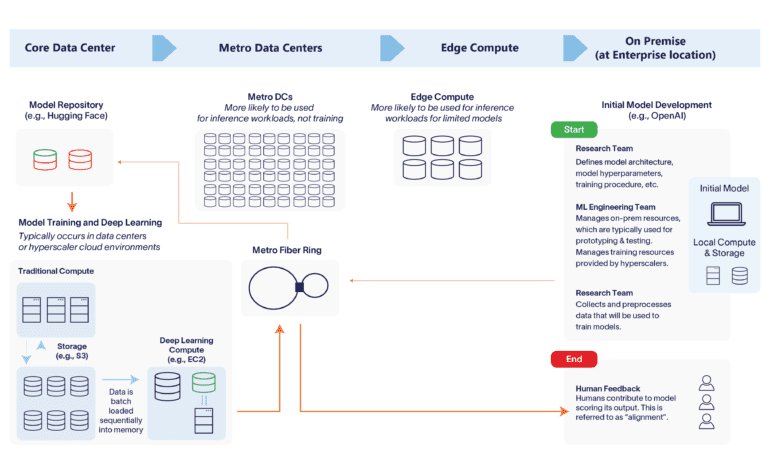
Altman Solon foresees growth in demand for compute resources due to the increasing adoption of enterprise-level generative AI tools. This growth will benefit core, centralized data centers, where training takes place, and local data centers, where inference happens. In this context, network providers should anticipate a moderate rise in demand for data transit networks, as well as a notable surge in demand for private networking solutions.
To comprehend the impact on infrastructure, Altman Solon employed a meticulous four-step methodology, taking into account the average compute time required for each generative AI task, the overall volume of generative AI tasks, the additional compute requirements, and the quantifiable impact on the infrastructure value chain. In anticipation of this demand surge, service providers must proactively plan for adequate compute resources and network capacity.
Altman Solon’s groundbreaking research also involved a survey of 292 senior business leaders, revealing intriguing insights into enterprise generative AI use cases. Across key business functions such as software development, marketing, customer service, and product development/design, the hourly volume of generative AI tasks is predicted to reach a staggering 80-130 million within the next year in the United States alone.
Although customer service has been slower to adopt generative AI solutions compared to software development and marketing, it is expected to be the primary driver of generative AI usage for enterprises. This is primarily due to the sheer volume of user interactions with generative AI chatbots. Nonetheless, the process of developing and using generative AI solutions demands significant infrastructure support.
The development and use of generative AI tools necessitate compute resources in two distinct phases: model training and inference. Training an LLM involves feeding vast amounts of data to a neural network, as exemplified in the case of ChatGPT, where large amounts of text data were utilized to recognize patterns and language relationships. The GPT-3 model already encompasses over 175 billion parameters, while its successor, GPT-4, is speculated to boast a staggering 1 trillion parameters.
While training is compute-intensive and occurs only during the model’s development, inference constitutes the bulk of the workload. When a user submits a query, the generative AI application’s cloud environment processes the information, with 80-90% of compute workloads dedicated to inference. Running the model, therefore, surpasses training costs on a weekly basis.
The impact of housing and training generative AI solutions is most pronounced in centralized, core data centers equipped with the necessary GPUs to process vast amounts of data cycling through LLMs. Additionally, public clouds also play a crucial role in housing models, eradicating ingress and egress costs as the training data resides within the cloud. However, as generative AI matures and gains popularity, the inference is expected to move towards local data centers to alleviate congestion in core, centralized data centers where models are trained. Yet, limitations arise when attempting to house generative models in conventional edge locations due to higher real estate and power costs, making it challenging to accommodate resource-hungry AI workloads.
Nidhi Chappell, Microsoft General Manager of Azure AI infrastructure, notes that the creation of a reliable and scalable system architecture enabled the realization of ChatGPT. She believes there will be a plethora of similar models arising in the future.
Considering the implications across the infrastructure value chain, infrastructure providers must adapt proactively to meet the increased demand in compute, networking, and storage resources. Core, centralized data centers must focus on capacity planning to cater to training and inference workloads. Cloud providers can mitigate congestion risks by providing compute capacity in regional availability zones capable of handling heavy generative AI workloads. Additionally, considering the demand channeled through model providers like Cohere and OpenAI, core data centers should explore exclusive partnerships while also pursuing open-source collaborations to avoid overreliance on a single provider.
Backbone and metro fiber providers must enhance network capacity and egress bandwidth to cope with the increased demand originating from training data, inference prompts, and model outputs. The emphasis on data privacy and residency is expected to drive increased demand for private WAN solutions. As AI models become more dispersed across different cloud providers and compute environments, backbone fiber providers can address latency concerns through interconnects and peering.
Metro data centers and edge compute locations may witness a shift towards inference workloads, while smaller generative AI models could be optimized for readily available CPUs in edge data centers. For access networks, the increase in demand will resemble early generative AI traffic, which may gradually evolve to incorporate more complex and voluminous data. On-premise hardware, although not suitable for generative AI models currently, remains a topic of active research due to data privacy concerns and the potential appeal of running LLMs locally on mobile devices.
Conclusion:
The rise of generative AI is transforming the market landscape, compelling businesses to prepare for a surge in compute, storage, and networking demands. Cloud providers and data centers must proactively plan for capacity expansion, while network providers should enhance infrastructure to accommodate the growing traffic. With the potential for more distributed AI models and optimization at the edge, the market will witness significant changes in infrastructure requirements, necessitating continuous innovation and adaptability for sustained growth and success.