
TL;DR:
- UC Berkeley introduces Ghostbuster, an AI method for identifying LLM-generated text.
- Language models like ChatGPT have raised concerns due to factual errors and content authenticity.
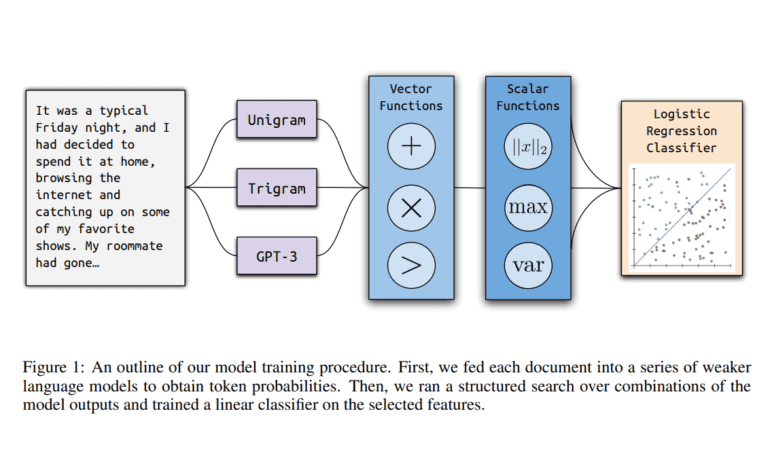
- Ghostbuster employs a three-stage training process, including probability computation, feature selection, and classifier training.
- It outperforms other detection frameworks, achieving a remarkable 97.0 F1 score.
- Ghostbuster’s robust performance has significant implications for content authentication.
Main AI News:
The era of AI-powered language models, exemplified by ChatGPT, has undeniably transformed the landscape of content creation across diverse subjects. Nevertheless, the question of their reliability looms large. These language models, while capable of producing coherent text, are not impervious to factual inaccuracies and fabrications. The prevalence of AI-generated text in news articles and informative materials has led to concerns about the credibility and originality of such content. Consequently, many educational institutions have imposed restrictions on the use of ChatGPT and similar tools due to their potential to produce content with ease.
Language models like ChatGPT operate by generating responses based on patterns and information gleaned from extensive training on vast textual datasets. They do not replicate text verbatim but instead create new content by predicting and comprehending the most suitable continuation for a given input. However, these generated responses may inadvertently draw upon and synthesize information from their training data, resulting in resemblances to existing content. It’s crucial to recognize that while these models aspire to achieve originality and accuracy, they are not infallible. Users must exercise discernment and avoid sole reliance on AI-generated content for critical decision-making or situations necessitating expert guidance.
Numerous detection frameworks, such as DetectGPT and GPTZero, have been developed to discern whether a language model has authored the content. However, the performance of these frameworks is compromised when applied to datasets they were not initially evaluated. Enter the researchers from the University of California, who introduce Ghostbuster, a revolutionary method for content detection founded on a structured search and linear classification approach.
Ghostbuster embarks on a three-stage training journey, commencing with probability computation, followed by feature selection, and culminating in classifier training. Initially, it transforms each document into a series of vectors by computing per-token probabilities under a spectrum of language models. Subsequently, it identifies pertinent features through an exhaustive structured search process, exploring a plethora of vector and scalar functions that amalgamate these probabilities. This is achieved by defining a comprehensive set of operations that combine these features, ultimately leading to forward feature selection. In the final phase, Ghostbuster trains a straightforward classifier using the most promising probability-based features, complemented by a selection of manually curated features.
Ghostbuster’s classifiers are honed through a fusion of probability-based features, meticulously chosen via structured search and an additional array of features rooted in word length and token probabilities. These supplementary features are strategically designed to incorporate qualitative heuristics observed in AI-generated text.
The performance gains achieved by Ghostbuster exhibit robustness across different training and testing datasets. Impressively, Ghostbuster attains a remarkable 97.0 F1 score, averaged across all conditions, outclassing DetectGPT by an impressive 39.6 F1 points and GPTZero by 7.5 F1 points. Moreover, Ghostbuster surpasses the RoBERTa baseline in all domains except creative writing out-of-domain, with RoBERTa exhibiting notably inferior out-of-domain performance. It’s worth noting that the F1 score, a widely recognized metric for evaluating classification model performance, amalgamates precision and recall into a singular value, rendering it particularly valuable when confronted with imbalanced datasets.
Conclusion:
The unveiling of Ghostbuster by UC Berkeley marks a pivotal moment in the ongoing quest to authenticate the origins of AI-generated content. With its cutting-edge methodology and exceptional performance, Ghostbuster emerges as a formidable guardian against the proliferation of potentially deceptive or unoriginal text. As the landscape of AI-generated content continues to evolve, Ghostbuster stands as a testament to the relentless pursuit of accuracy and credibility in an era dominated by language models like ChatGPT.