
- Google introduces Croissant, a metadata format for ML-ready datasets.
- Croissant streamlines data organization and enhances discoverability in ML development.
- It augments existing standards like schema.org, catering specifically to ML data requirements.
- Croissant promotes Responsible AI (RAI) practices through dedicated extensions.
- The adoption of Croissant by major ML platforms and repositories accelerates its integration into the ecosystem.
- Croissant simplifies dataset publishing and consumption, fostering collaboration and innovation in ML research.
Main AI News:
As the realm of machine learning (ML) expands, navigating through diverse datasets becomes a crucial aspect for experts in the field. The process of deciphering data structures and selecting relevant subsets for feature extraction often presents a formidable challenge. This challenge is compounded by the plethora of data formats available, posing a significant hurdle to progress in ML innovation.
In ML datasets, which encompass various content categories such as text, structured data, photos, audio, and video, the absence of a standardized file layout or data format further complicates matters. This lack of uniformity not only impedes productivity across the spectrum of ML development stages but also hinders the creation of essential tools for managing extensive datasets.
While existing database metadata formats like schema.org and DCAT offer some solutions, they fail to address the specific requirements of ML data. These requirements include the need to seamlessly integrate structured and unstructured data sources, incorporate metadata for responsible data usage, and delineate ML usage characteristics such as training, test, and validation sets.
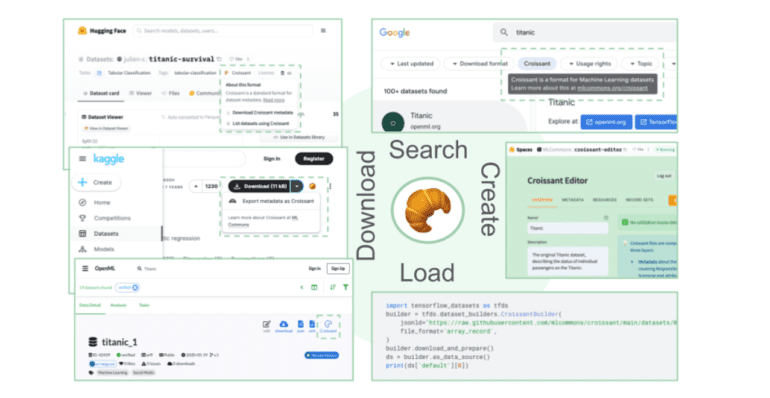
In response to these challenges, Google has unveiled Croissant, a novel metadata format tailored for ML-ready datasets. The Croissant framework, accompanied by comprehensive specifications, sample datasets, and an open-source Python library, streamlines the validation, consumption, and generation of metadata. Furthermore, the 1.0 release of Croissant introduces a user-friendly visual editor, empowering users to effortlessly create and inspect dataset descriptions.
While Croissant maintains data representation integrity, it augments the existing schema.org standard, which serves as the cornerstone for structured data publication online. By incorporating additional layers for data resources, default ML semantics, metadata, and data management, Croissant emerges as a pivotal extension of this standard, enhancing its relevance in the realm of ML.
At its core, the Croissant initiative is driven by a commitment to fostering Responsible AI (RAI) practices. In tandem with the initial Croissant release, Google has unveiled the Croissant RAI vocabulary extension. This extension enriches Croissant by introducing properties tailored to diverse RAI use cases, including data life cycle management, labeling, safety and fairness evaluation, explainability, and compliance.
The adoption of Croissant holds significant benefits for both dataset creators and consumers. By leveraging readily available generation tools and support from ML data platforms, creators can effortlessly enhance the discoverability and utility of their datasets. Moreover, the integration of Croissant metadata facilitates seamless dataset discovery and reuse, streamlining processes for both creators and consumers.
To further catalyze the adoption of Croissant, prominent ML dataset repositories and search engines, including Kaggle, Hugging Face, and OpenML, have pledged support for the format. With datasets easily discoverable through tools like Dataset Search and frameworks like TensorFlow, PyTorch, and JAX offering seamless integration with Croissant datasets, the landscape of ML research and development is poised for enhanced efficiency and collaboration.
Conclusion:
The introduction of Croissant marks a significant milestone in advancing the accessibility and usability of ML-ready datasets. By embracing standardized metadata formats like Croissant, stakeholders across the ML ecosystem can collectively alleviate the burdens associated with data development, paving the way for a more robust and collaborative environment conducive to ML innovation.