
TL;DR:
- Google introduces MediaPipe diffusion plugins for on-device text-to-image generation with user control.
- These plugins enhance image quality, inference performance, and creative possibilities.
- They enable integration with existing diffusion models and Low-Rank Adaptation (LoRA) variations.
- Control information from a condition image is introduced to convey challenging details.
- Plug-and-Play, ControlNet, and T2I Adapter methods are commonly used for controlled text-to-image output.
- MediaPipe diffusion plugins offer a standalone network with seamless integration and a relatively low parameter count.
- The plugins are portable, run independently on mobile devices, and incur minimal additional costs.
- Multiscale feature extraction and MobileNetv2 ensure efficient and rapid inference.
Main AI News:
In recent years, the use of diffusion models has revolutionized the field of text-to-image generation, bringing about remarkable advancements in image quality, inference performance, and the realm of creative possibilities. However, effectively managing the generation process under ill-defined conditions has remained a challenge. Addressing this, Google researchers have developed MediaPipe diffusion plugins, empowering users with control over on-device text-to-image generation.
Expanding on their previous work on GPU inference for large generative models, the researchers present cost-effective solutions for programmable text-to-image creation that seamlessly integrate with existing diffusion models and their Low-Rank Adaptation (LoRA) variations.
Central to diffusion models is the concept of iterative denoising, which drives the image production process. Each iteration starts with a noise-contaminated image and culminates in a refined target image. Text prompts have significantly enhanced language understanding and facilitated the image generation process. To establish a connection between text embedding and the model for text-to-image production, cross-attention layers play a crucial role. However, conveying intricate details like object position and pose through text prompts can pose a greater challenge. To address this, researchers introduce control information from a conditional image into diffusion using supplementary models.
Several methods, such as Plug-and-Play, ControlNet, and T2I Adapter, are commonly employed to generate controlled text-to-image output. Plug-and-Play utilizes a copy of the diffusion model and a denoising diffusion implicit model (DDIM) inversion approach to encode the state from an input image. Spatial features with self-attention extracted from the copied diffusion are then injected into the text-to-image diffusion, facilitating controlled generation. ControlNet, on the other hand, creates a trainable duplicate of the encoder of a diffusion model, which is connected to the decoder layers via a convolution layer with zero-initialized parameters. Unfortunately, this approach significantly increases the size of the model. T2I Adapter, a smaller network with 77M parameters, delivers comparable results in a controlled generation. It takes the condition picture as the sole input and utilizes the result across subsequent diffusion cycles. However, this adapter is not optimized for mobile devices.
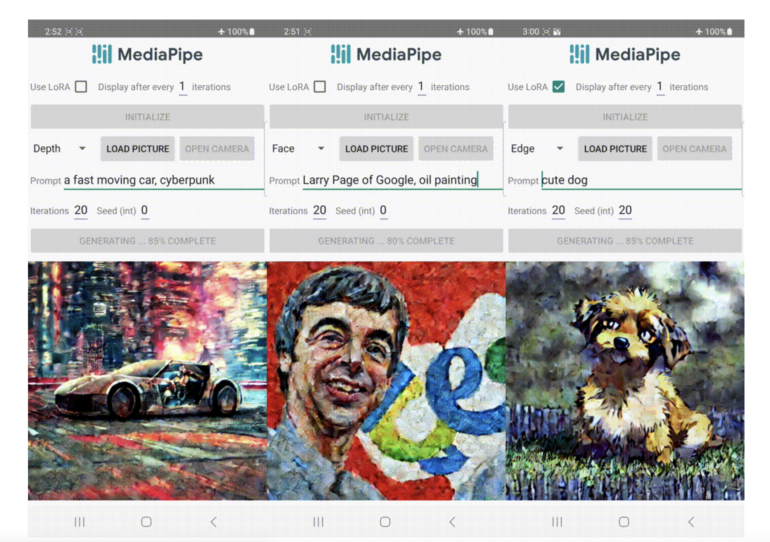
Enter the MediaPipe diffusion plugin—a standalone network developed to enable effective, flexible, and scalable conditioned generation. This plugin seamlessly connects to a trained baseline model, requiring zero weights from the original model. Notably, it can run independently of the base model on mobile devices without incurring substantial additional costs. Acting as its own network, the plugin produces results that can be integrated into existing models for text-to-image conversion. The corresponding downsampling layer of the diffusion model receives the retrieved features from the plugin, ensuring a smooth integration.
The MediaPipe dispersion plugin represents a portable on-device paradigm for text-to-image creation and is available as a free download. It takes a conditioned image and employs multiscale feature extraction to enhance the encoder of a diffusion model with features at appropriate scales. When combined with a text-to-image diffusion model, the plugin model introduces a conditioning signal that influences the image production process. With a modest parameter count of 6M, the plugin network offers simplicity alongside rapid inference on mobile devices, leveraging depth-wise convolutions and inverted bottlenecks powered by MobileNetv2.
Key Characteristics:
- Easy-to-understand abstractions for self-service machine learning, enabling modification, testing, prototyping, and application release through low-code APIs or no-code studios.
- Innovative machine learning approaches, harnessing Google’s ML expertise to tackle common problems.
- Comprehensive optimization, including hardware acceleration, while maintaining a small and efficient footprint for seamless performance on battery-powered smartphones.
Conclusion:
Google AI’s introduction of MediaPipe diffusion plugins for on-device text-to-image generation signifies a significant advancement in the market. These plugins offer enhanced control, improved image quality, and efficient integration with existing models. The ability to convey challenging details through control information and the compatibility with different methods make them valuable asset for businesses and creative professionals. The portability and low parameter count further enhance their appeal, allowing seamless usage on mobile devices while minimizing additional expenses. This innovation opens new avenues for self-service machine learning, enabling businesses to modify, test, and prototype applications with ease, ultimately driving innovation and unlocking new possibilities in the market.