
- Google introduces PERL, a Parameter-Efficient Reinforcement Learning technique.
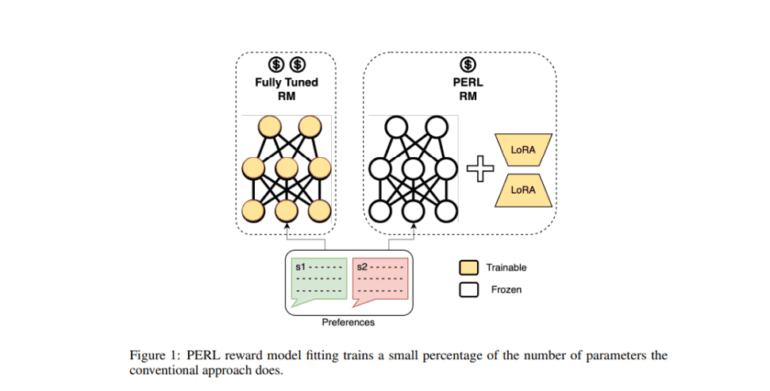
- PERL utilizes LoRA to refine models efficiently, reducing computational and memory requirements.
- It maintains high performance while significantly reducing memory usage and accelerating training.
- Diverse datasets, including conversational interactions, demonstrate PERL’s efficacy.
- PERL offers promise for robust cross-domain generalization and mitigating reward hacking risks.
Main AI News:
In the realm of Reinforcement Learning from Human Feedback (RLHF), the quest for aligning Pretrained Large Language Models (LLMs) with human values has been fraught with challenges. Despite its potential, RLHF encounters obstacles stemming from its computational intensity and resource requirements, hindering widespread adoption.
To address these challenges, various techniques such as RLHF, RLAIF, and LoRA have emerged. While RLHF involves fitting a reward model on preferred outputs and training a policy using reinforcement learning algorithms like PPO, it grapples with the costly labeling of examples for training reward models. In response, methods like Parameter Efficient Fine-Tuning (PEFT) have emerged to reduce the number of trainable parameters in PLMs while sustaining performance.
Google’s research team now unveils a groundbreaking methodology called Parameter-Efficient Reinforcement Learning (PERL), which harnesses the power of LoRA to refine models with unparalleled efficiency. By selectively training adapters while preserving the core model, PERL drastically reduces memory footprint and computational load without compromising performance.
PERL’s innovation extends to its diverse range of datasets, spanning text summarization, response preference modeling, helpfulness metrics, UI Automation tasks, and conversational interactions. Leveraging crowdsourced Taskmaster datasets, PERL demonstrates remarkable efficiency in aligning with RLHF outcomes, slashing memory usage by 50% and accelerating Reward Model training by up to 90%.
Moreover, LoRA-enhanced models exhibit accuracy on par with fully trained counterparts, utilizing only half the peak HBM usage and boasting 40% faster training times. This qualitative leap underscores PERL’s ability to maintain high performance while significantly reducing computational demands.
Conclusion:
The introduction of Google’s PERL marks a significant milestone in reinforcement learning techniques. By leveraging LoRA for efficiency, PERL not only streamlines model training but also promises enhanced performance across various datasets. This innovation signifies a potential shift in the market towards more efficient and effective reinforcement learning methods, offering opportunities for businesses to improve their AI applications while reducing computational costs.