
TL;DR:
- Translatotron 3 is a groundbreaking unsupervised Speech-to-Speech Translation (S2ST) technology by Google AI.
- It addresses the challenge of scarce parallel speech data by learning solely from monolingual data.
- The architecture includes pre-training with SpecAugment, unsupervised embedding mapping using MUSE, and back-translation.
- Translatotron 3 outperforms existing models in translation quality, speaker similarity, and speech quality.
- It preserves non-textual speech attributes like pauses and speaking rates, offering naturalness comparable to real audio.
- This innovation has the potential to revolutionize global communication by bridging linguistic gaps and enhancing S2ST versatility.
Main AI News:
In the realm of language technology, speech-to-speech translation (S2ST) has been a game-changer, shattering linguistic barriers and fostering global communication. However, its progress has been stymied by the scarcity of parallel speech data, leaving most existing models reliant on supervised settings and grappling with the intricacies of translating speech and reconstructing speech attributes from synthesized training data.
Google AI’s previous endeavors in this domain, Translatotron 1 and Translatotron 2, made commendable strides by directly translating speech between languages. Nevertheless, they were limited by their dependence on supervised training, where parallel speech data was a rare commodity. The crux of the matter lies in the challenge of obtaining sufficient parallel data, making the training of S2ST models an intricate affair. Enter Translatotron 3, a groundbreaking solution introduced by Google’s research team.
The astute researchers recognized that most publicly available datasets for speech translation were either semi-synthesized or fully synthesized from text, posing additional challenges in teaching models the art of translation and accurately reconstructing speech attributes embedded in the text. In response, Translatotron 3 ushers in a paradigm shift by embracing the concept of unsupervised S2ST, a method that endeavors to learn the translation task solely from monolingual data. This innovation opens up new horizons for translation across diverse language pairs and introduces the capacity to translate non-textual speech attributes, including pauses, speaking rates, and speaker identity.
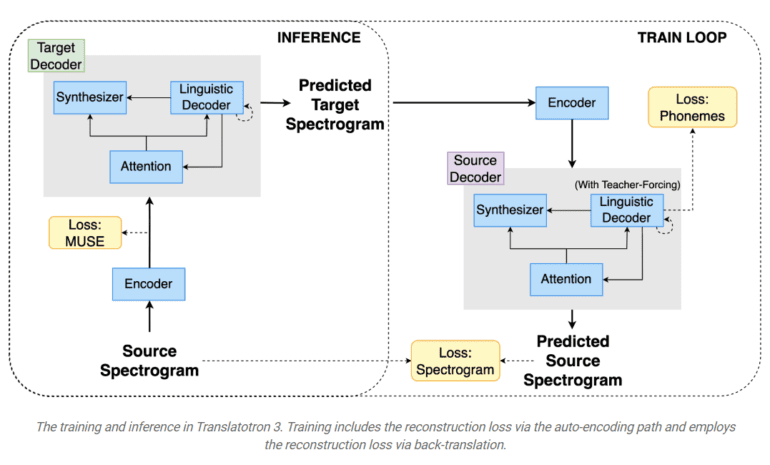
Translatotron 3’s architecture revolves around three pivotal components, strategically designed to tackle the challenges of unsupervised S2ST:
- Pre-training as a Masked Autoencoder with SpecAugment: The entire model undergoes pre-training as a masked autoencoder, harnessing the power of SpecAugment, a simple yet effective data augmentation technique for speech recognition. SpecAugment operates on the logarithmic mel spectrogram of the input audio, enhancing the encoder’s ability to generalize.
- Unsupervised Embedding Mapping based on Multilingual Unsupervised Embeddings (MUSE): Translatotron 3 leverages MUSE, a technique trained on unpaired languages that empowers the model to cultivate a shared embedding space between source and target languages. This shared embedding space streamlines the encoding of input speech, rendering it more efficient and effective.
- Reconstruction Loss through Back-Translation: The model’s training regimen combines unsupervised MUSE embedding loss, reconstruction loss, and S2S back-translation loss. During inference, a shared encoder encodes the input into a multilingual embedding space, which is subsequently decoded by the target language decoder.
Translatotron 3’s training methodology encompasses auto-encoding with reconstruction and a back-translation term. In the first phase, the network learns to auto-encode the input into a multilingual embedding space using MUSE loss and reconstruction loss, ensuring that the network generates meaningful multilingual representations. The second phase focuses on training the network to translate the input spectrogram using the back-translation loss, with the MUSE loss and reconstruction loss applied to enforce the multilingual nature of the latent space. SpecAugment plays a crucial role in both phases, guaranteeing the acquisition of meaningful properties.
Empirical evaluations of Translatotron 3 underline its supremacy over a baseline cascade system, particularly excelling in preserving conversational nuances. The model exhibits remarkable performance in translation quality, speaker similarity, and speech quality. Despite its unsupervised nature, Translatotron 3 proves to be a robust solution, delivering results that surpass existing systems. Its ability to achieve speech naturalness akin to ground truth audio samples, as gauged by the Mean Opinion Score (MOS), underscores its effectiveness in real-world scenarios.
Translatotron 3 emerges as a pioneering solution to the challenge of unsupervised S2ST, brought about by the scarcity of parallel speech data. By learning exclusively from monolingual data and harnessing the power of MUSE, the model achieves unmatched translation quality while preserving crucial non-textual speech attributes. The research team’s innovative approach marks a significant stride toward making speech-to-speech translation more versatile and effective across a wide spectrum of language pairs. Translatotron 3’s resounding success in outperforming existing models signifies its potential to revolutionize the field and elevate communication among diverse linguistic communities. In forthcoming endeavors, the team aims to expand the model to encompass more languages and explore its applicability in zero-shot S2ST scenarios, thereby further amplifying its impact on global communication.
Conclusion:
Translatotron 3’s revolutionary approach to unsupervised S2ST technology not only overcomes the scarcity of parallel speech data but also outperforms existing models in various aspects. Its impact on the market is poised to revolutionize global communication, offering more versatile and effective speech-to-speech translation capabilities, thereby opening doors to enhanced collaboration and understanding among diverse linguistic communities.