
- Google introduces Cappy, a pre-trained scorer model aiming to enhance the performance of large multi-task language models (LLMs).
- Challenges faced by LLMs due to their immense size demand significant computational resources for training and inference.
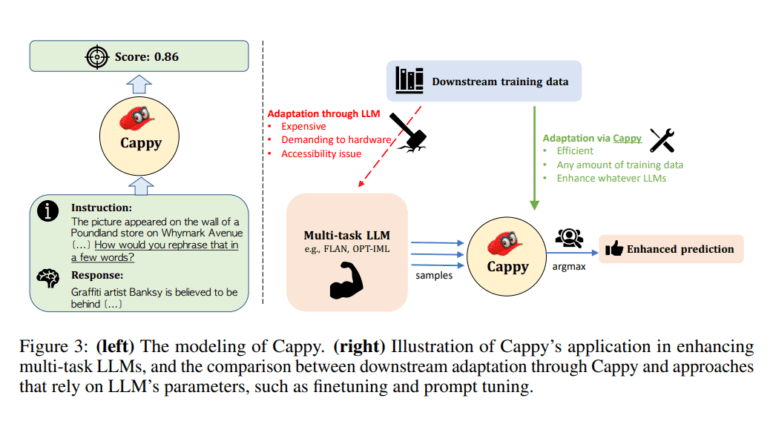
- Cappy, based on RoBERTa’s architecture, employs a linear layer for regression tasks and utilizes a diverse dataset collection for pretraining from PromptSource.
- Cappy addresses the need for label diversity in pretraining data through a novel approach involving ground truth pairs, incorrect responses, and data augmentation.
- Its candidate selection mechanism generates scores for potential responses based on given instructions, enhancing performance in classification and generation tasks.
- Cappy enables efficient adaptation of multi-task LLMs to downstream applications without extensive fine-tuning or access to LLM parameters.
Main AI News:
In the realm of AI innovation, Google has introduced Cappy, a pre-trained scorer model aimed at elevating and surpassing the capabilities of large multi-task language models (LLMs). This breakthrough, detailed in a recent research paper, seeks to address the challenges posed by the scale and resource requirements of LLMs while maintaining and enhancing their performance across diverse natural language processing tasks.
Large language models have demonstrated exceptional performance and adaptability across various NLP tasks. However, their colossal size necessitates significant computational resources, rendering training and inference costly and inefficient, particularly for downstream applications.
Presently, multi-task LLMs such as T0, FLAN, and OPT-IML serve diverse NLP tasks within a unified framework. Yet, their application to complex tasks remains hindered by hardware demands and limited accessibility to the most potent LLMs. In response, Google’s research introduces Cappy—a nimble pre-trained scorer engineered to augment the efficiency and efficacy of multi-task LLMs.
Drawing inspiration from the architecture of RoBERTa, Cappy integrates a linear layer for regression tasks. Its pretraining strategy leverages a comprehensive dataset assortment from PromptSource, ensuring coverage across a spectrum of task types. To address the imperative of label diversity, researchers devise a novel data construction methodology incorporating ground truth pairs, erroneous responses, and data augmentation via existing multi-task LLMs, resulting in a robust regression pretraining dataset.
Central to Cappy’s functionality is its candidate selection mechanism, generating scores for each potential response based on given instructions. This versatile model operates autonomously for classification tasks or synergistically enhances the performance of generation tasks when integrated with multi-task LLMs.
Moreover, Cappy facilitates seamless adaptation of multi-task LLMs to downstream applications without necessitating extensive fine-tuning or access to LLM parameters. This agility and versatility position Cappy as a pivotal advancement in the realm of AI-driven natural language processing, promising heightened efficiency and performance across a broad spectrum of applications.
Conclusion:
The introduction of Cappy marks a significant advancement in the AI-driven natural language processing market. Its ability to enhance the performance of large multi-task language models while mitigating computational resource demands and simplifying adaptation processes heralds increased efficiency and accessibility for businesses utilizing NLP technologies. With Cappy’s versatility and agility, companies can expect improved productivity and effectiveness in a wide range of applications, positioning them competitively in the rapidly evolving landscape of AI innovation.