
TL;DR:
- Google DeepMind research explores the use of CLIP-based vision-language models (VLMs) for RL agent reward generation.
- Larger VLMs yield more accurate rewards, improving RL agent capabilities.
- The study highlights the conversion of reward functions into binary form through probability thresholding.
- Off-the-shelf VLMs, particularly CLIP, show promise in training versatile RL agents in diverse tasks.
- Contrastive VLMs like CLIP construct text-based reward models for RL agents with image and text encoders.
- Pre-trained CLIP models are used in experiments across Playhouse and AndroidEnv domains.
- Various encoder architectures, including Normalizer-Free Networks, Swin, and BERT, are explored for language encoding.
Main AI News:
Reinforcement learning (RL) agents epitomize the essence of artificial intelligence by embodying adaptive prowess. They navigate intricate knowledge landscapes through iterative trial and error, dynamically assimilate environmental insights, and autonomously evolve to optimize their decision-making capabilities. Developing versatile generalist RL agents capable of performing diverse tasks in complex environments remains a formidable challenge that hinges on the definition of numerous reward functions. However, researchers are exploring innovative strategies to surmount this obstacle.
Google DeepMind researchers have embarked on an exploration of leveraging off-the-shelf vision-language models (VLMs), with a specific focus on the CLIP family. These models hold the potential to derive rewards for training RL agents that can proficiently tackle a wide array of language-related objectives. Through experiments conducted in two distinct visual domains, their research underscores a noteworthy trend: the utilization of larger VLMs results in rewards of heightened accuracy, thereby augmenting the capabilities of RL agents. Furthermore, the study delves into the conversion of reward functions into a binary format through the implementation of probability thresholding techniques. The experiments conducted address VLM reward maximization and scaling impact, offering insights into the possibility of training generalist RL agents in rich visual environments without the need for task-specific finetuning.
The central objective of this research is to tackle the daunting challenge of creating adaptable RL agents capable of achieving diverse goals within complex environments. Traditional RL relies heavily on explicit reward functions, which often pose difficulties when defining varied objectives. To address this conundrum, the study explores the potential of harnessing VLMs, particularly the highly effective CLIP model. VLMs, like CLIP, are trained on extensive image-text data and exhibit promising performance across a range of visual tasks, making them ideal candidates for generating effective reward functions. The research revolves around the investigation of using off-the-shelf VLMs to derive precise rewards, with a particular emphasis on language-related objectives in visual contexts. The overarching goal is to streamline the training of RL agents by incorporating VLM-based rewards.
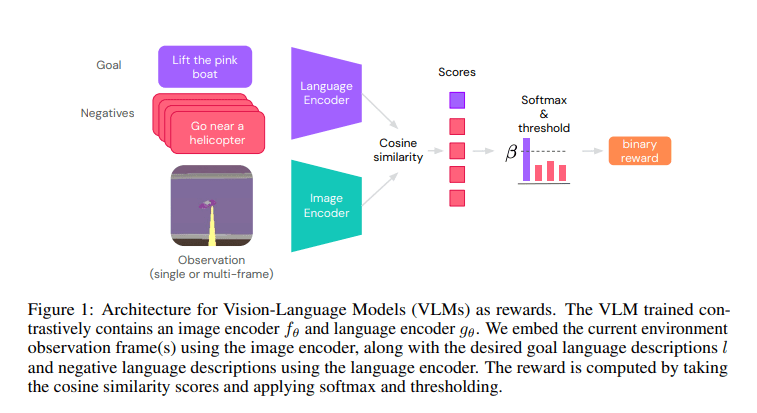
In practical terms, the study employs contrastive VLMs such as CLIP to construct text-based reward models for reinforcement learning agents. These models comprise both image and text encoders, generating binary rewards that signify goal achievement. Operating within the framework of a partially observed Markov Decision Process, the study calculates rewards using a VLM that processes scanned images and interprets language-based objectives. Throughout the experimentation phase, pre-trained CLIP models are utilized across various tasks within Playhouse and AndroidEnv domains. The study also explores different encoder architectures, including Normalizer-Free Networks, Swin, and BERT, for language encoding in tasks such as Find, Lift, and Pick and Place.
The core premise of this approach revolves around the utilization of off-the-shelf VLMs, specifically CLIP, as reliable sources for rewarding RL agents. The study demonstrates the feasibility of deriving rewards for a multitude of language-related objectives from CLIP, thereby training RL agents to excel across a wide range of tasks within the Playhouse and AndroidEnv domains. It becomes evident that the utilization of larger VLMs results in more precise rewards, ultimately enhancing the capabilities of RL agents. Scaling up the size of VLMs consistently leads to improved performance. Additionally, the research explores the impact of prompt engineering on VLM reward performance, although specific results from the sources remain undisclosed.
Conclusion:
The research indicates that leveraging CLIP-based vision-language models for reward generation in reinforcement learning can significantly enhance the capabilities of RL agents. This approach offers the potential to streamline RL agent training, making it more adaptable to diverse tasks in complex environments. As a result, this innovation could lead to the development of highly versatile and capable AI systems, opening up new opportunities in various markets where AI-driven automation and decision-making are essential.