
TL;DR:
- Google Research introduces Generative Infinite-Vocabulary Transformers (GIVT) for AI tasks.
- GIVT allows transformers to work with real-valued vector sequences, bypassing finite vocabularies.
- Key modifications: Input as real-valued vectors, output as parameters of continuous distribution.
- GIVT retains teacher forcing and causal attention masks, exploring progressive masked-bidirectional modeling.
- Solves challenges in modeling intricate sequences like high-resolution image pixels.
- Achieves superior performance in dense prediction tasks and picture synthesis.
- Advances in sampling methods, including temperature sampling and classifier-free guiding.
- GIVT’s use of real-valued tokens outperforms traditional discrete-token transformers.
- Examines the relationship between VAE latent-space regularization and GIVT’s characteristics.
Main AI News:
Transformers, the stalwarts of natural language processing, have made their triumphant mark in computer vision as well. Google Research, in collaboration with Google DeepMind, has introduced an innovative breakthrough in the form of Generative Infinite-Vocabulary Transformers (GIVT), revolutionizing the way we approach AI-driven tasks.
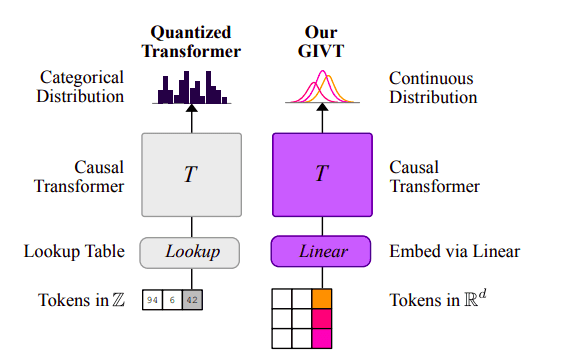
Traditionally, transformers have excelled in language processing by utilizing discrete tokens from a predefined vocabulary. However, when it comes to generating visual content, this approach falls short. This is where GIVT steps in, offering a new paradigm by enabling transformers to work with real-valued vector sequences, effectively eliminating the constraints imposed by limited vocabularies.
The GIVT model brings about two crucial modifications. First, it linearly embeds a sequence of real-valued vectors as input, departing from the conventional practice of looking up embeddings from a finite vocabulary of discrete tokens. Second, it predicts the parameters of a continuous distribution over real-valued vectors at the output, as opposed to predicting categorical distributions over finite vocabularies. This transformative approach retains the essence of teacher forcing and causal attention masks, akin to typical transformer decoders, while also exploring progressive masked-bidirectional modeling methods.
Handling intricate sequences, such as the pixels in high-resolution images, is a formidable challenge for conventional methods. GIVT offers a solution by training a lower-dimensional latent space using a Gaussian-prior Variational Autoencoder (VAE) and subsequently modeling it. This two-step technique aligns with the principles of VQ-VAEs and latent-diffusion models. The incorporation of proven inference strategies, such as temperature sampling and classifier-free guiding, further enhances GIVT’s capabilities.
Remarkably, GIVT’s reliance solely on real-valued tokens results in superior or equivalent performance compared to traditional discrete-token transformer decoders. Its key contributions are threefold:
- Enhanced Performance: GIVT outperforms traditional discrete-token transformer decoders in dense prediction tasks, including semantic segmentation, depth estimation, and picture synthesis, thanks to its innovative approach.
- Sampling Advancements: The research team has harnessed and substantiated variations of traditional sampling methods in the continuous case, including temperature sampling, beam search, and classifier-free guiding (CFG), further cementing GIVT’s versatility.
- Understanding Latent Space: Through meticulous examination of KL-term weighting, the research team sheds light on the relationship between VAE latent-space regularization and the emerging characteristics of GIVT. Notably, GIVT relies on standard deep-learning toolbox approaches, eschewing the complex training methods of the VQ-VAE literature.
Conclusion:
GIVT represents a monumental leap in AI, liberating transformers from the confines of discrete tokens and finite vocabularies. Its real-valued vector sequences open doors to a new era of AI-driven tasks, where flexibility, efficiency, and performance converge to reshape the landscape of artificial intelligence. Google Research and Google DeepMind have once again pushed the boundaries of what’s possible in the realm of AI, and the future looks promising with GIVT leading the way.