
TL;DR:
- Google Research introduces a pioneering AI approach for modeling image-space scene dynamics.
- Motion in seemingly static images is driven by natural forces, and replicating this realism is a complex AI challenge.
- The model is trained to predict pixel motion trajectories based on motion basis coefficients, achieving impressive results.
- Fourier series basis functions are employed, focusing on oscillating dynamics like swaying trees and dancing flowers.
- The generated motion textures enable lifelike animations, offering finer control and coherence compared to traditional methods.
- Applications extend to looping videos, motion editing, and interactive dynamic images.
- This advancement redefines the possibilities in visual storytelling and animation.
Main AI News:
In the ever-dynamic realm of artificial intelligence, Google Research is making waves with a groundbreaking approach to modeling image-space scene dynamics. In a world constantly in motion, even the stillest of images exhibit subtle oscillations brought about by various natural forces, from wind and water currents to the rhythmic ebb and flow of breath. It is this inherent motion that captures the human eye and adds depth to visual storytelling. Yet, teaching a machine to grasp and replicate such realistic movements within a scene is a complex endeavor.
The essence of motion lies in the physical dynamics of a scene, where forces act upon objects based on their unique physical attributes, including mass and elasticity. Quantifying and capturing these forces at scale poses significant challenges. However, the silver lining is that often they don’t need to be precisely quantified. Instead, they can be discerned and learned from the observable motion itself. Despite its multi-modal and intricate nature, this observed motion often follows predictable patterns. For instance, candles flicker in specific ways, and trees sway in harmony with the wind, creating a symphony of motion that our human perception seamlessly comprehends.
Translating this predictability into a digital realm becomes a fascinating research pursuit, considering how effortlessly humans envision potential movements. Thanks to recent strides in generative models, especially conditional diffusion models, we now have the capability to simulate rich and intricate distributions, even conditioning them on text. This newfound power unlocks a world of possibilities, including the creation of random, diverse, and realistic visual content based on textual prompts. Recent research demonstrates that extending these modeling techniques to other domains, such as videos and 3D geometry, holds immense potential for downstream applications, further expanding the horizons of visual innovation.
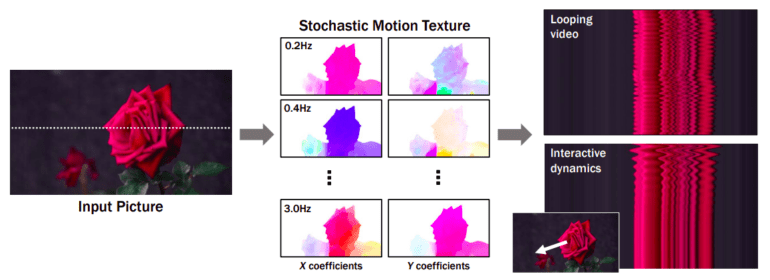
In their latest paper, researchers from Google Research delve into the art of modeling a generative prior for the motion of every pixel within a single image, a concept known as scene motion in image space. Their model is honed through the automated extraction of motion trajectories from an extensive array of real video sequences. Once trained, this model has the capacity to predict a neural stochastic motion texture based on an input image, driven by a collection of motion basis coefficients that delineate the future trajectory of each pixel.
The choice of Fourier series as the basis functions is strategic, confining their analysis to real-world scenarios featuring oscillating dynamics, such as trees swaying and flowers dancing in the wind. The model generates a neural stochastic motion texture via a diffusion model that computes coefficients for one frequency at a time, artfully coordinating these predictions across different frequency bands.
As depicted in Figure 1, these generated frequency-space textures can be transformed into dense, long-range pixel motion trajectories. This transformative process utilizes an image-based rendering diffusion model to synthesize forthcoming frames, effectively turning static images into lifelike animations. The significance of this approach lies in its foundational structure, as priors over motion capture exhibit a more basic, lower-dimensional underlying structure than priors over raw RGB pixels. Consequently, it offers a more profound understanding of pixel value fluctuations.
In contrast to earlier techniques relying on raw video synthesis for visual animation, this motion representation offers a more coherent and finer-grained control over animations, facilitating a higher degree of long-term production coherence. Moreover, the researchers showcase the versatility of their generated motion representation, which can be seamlessly applied to various downstream applications. This includes the creation of looping videos, the ability to edit induced motion, and the development of interactive dynamic images simulating how objects respond to user-applied forces.
Conclusion:
Google Research’s innovative AI breakthrough in modeling image-space scene dynamics has far-reaching implications for the market. It not only enhances the realism of visual content but also expands creative horizons in various industries. From entertainment to advertising, this technology promises to revolutionize how businesses engage with audiences, offering a new level of immersive and dynamic visual experiences. As AI-driven content generation becomes more accessible, companies that harness this cutting-edge capability will gain a competitive edge in captivating and captivating their target markets.