
TL;DR:
- Google’s groundbreaking ASR system revolutionizes multilingual speech recognition.
- Challenges like latency in processing spoken language have impeded progress in speech recognition technology.
- The non-autoregressive model by Google Research employs large language models and parallel processing to reduce latency.
- The fusion of the Universal Speech Model (USM) and PaLM 2 language model forms the core of this innovative system.
- Rigorous evaluation across languages and datasets demonstrates remarkable improvements in word error rates (WER).
- Considerations of language model size reveal the balance between model complexity and computational efficiency.
Main AI News:
In the realm of cutting-edge speech recognition technology, Google’s latest paper introduces an innovative Non-Autoregressive, LM-Fused ASR System that promises to revolutionize multilingual speech recognition. The journey of speech recognition technology has witnessed significant advancements, yet persistent challenges such as latency, the delay in processing spoken language, have hindered its progress. This latency is particularly pronounced in autoregressive models that process speech sequentially, causing undesirable delays. In applications demanding real-time performance, such as live captioning and virtual assistants, speed is of the essence. Finding solutions to tackle this latency issue while maintaining accuracy is paramount to advancing speech recognition.
A groundbreaking departure from conventional methods, this innovative model, developed by Google Research, seeks to address the inherent latency problems plaguing existing systems. It harnesses the power of massive language models and leverages parallel processing, a method that processes speech segments simultaneously rather than sequentially. This parallel approach is instrumental in significantly reducing latency, thereby providing users with a seamless and responsive experience.
At the heart of this cutting-edge model lies the fusion of the Universal Speech Model (USM) with the PaLM 2 language model. The USM, a robust model with a staggering 2 billion parameters, is meticulously crafted for precise speech recognition. It boasts a vocabulary of 16,384-word pieces and employs a Connectionist Temporal Classification (CTC) decoder for parallel processing. Trained on an extensive dataset comprising over 12 million hours of unlabeled audio and 28 billion sentences of text data, the USM excels in handling multilingual inputs.
Complementing the USM is the PaLM 2 language model, renowned for its prowess in natural language processing. This model is trained on a diverse range of data sources, including web documents and books, and boasts a vast 256,000 wordpiece vocabulary. What sets it apart is its ability to score Automatic Speech Recognition (ASR) hypotheses using a prefix language model scoring mode. This involves prompting the model with a fixed prefix, incorporating top hypotheses from previous segments, and subsequently scoring multiple suffix hypotheses for the current segment.
In practical implementation, the integrated system processes long-form audio in 8-second segments. As soon as the audio becomes available, the USM swiftly encodes it, and these segments are then transmitted to the CTC decoder. The decoder creates a confusion network lattice encoding possible word pieces, which are subsequently scored by the PaLM 2 model. The system updates itself every 8 seconds, offering a near real-time response that is nothing short of remarkable.
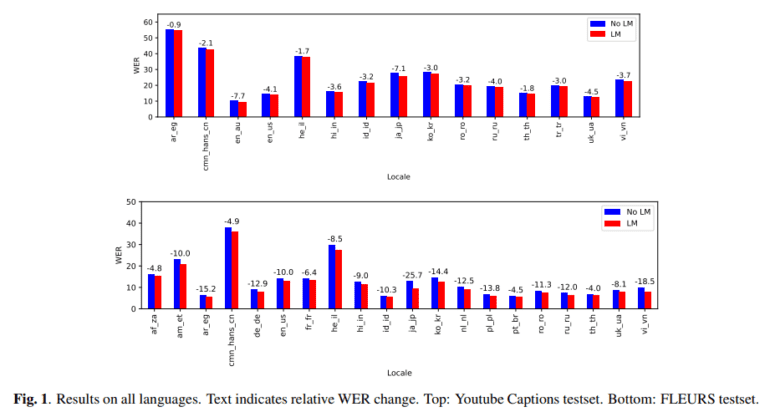
The performance of this model was subjected to rigorous evaluation across multiple languages and datasets, including YouTube captioning and the FLEURS test set. The results were nothing short of astounding. On the multilingual FLEURS test set, there was an average improvement of 10.8% in relative word error rate (WER). For the YouTube captioning dataset, a more challenging scenario, the model achieved an average improvement of 3.6% across all languages. These remarkable improvements serve as a testament to the model’s effectiveness in diverse linguistic and operational environments.
The study also delved into various factors influencing the model’s performance. It thoroughly examined the impact of language model size, ranging from 128 million to a staggering 340 billion parameters. The findings revealed that while larger models reduced sensitivity to fusion weight, the gains in WER might not offset the increasing inference costs. This underscores the delicate balance between model complexity and computational efficiency, which shifts with model size and needs to be carefully managed for optimal results in ASR systems.
Conclusion:
Google’s groundbreaking Non-Autoregressive ASR System promises to reshape the multilingual speech recognition landscape. By addressing latency issues in real-time applications and leveraging powerful language models, it offers a more responsive and accurate user experience. This innovation has the potential to open new opportunities and enhance efficiency in various market sectors, including virtual assistants, live captioning, and more, making it a significant development in the field of speech recognition technology.