
TL;DR:
- Google introduced Imagen 2, the second generation of its AI image generation model.
- The model, developed with technology from Google DeepMind, significantly improves image quality and adds text and logo rendering capabilities.
- Imagen 2 supports text rendering in multiple languages and overlaying logos on existing images.
- It can comprehend descriptive prompts and provide detailed responses, enhancing its multilingual understanding.
- The model employs SynthID to embed invisible watermarks in generated images.
- Google does not disclose the training data sources, raising legal questions.
- Google offers an indemnification policy for eligible Vertex AI customers.
- Concerns about “regurgitation” and intellectual property persist in the generative AI field.
Main AI News:
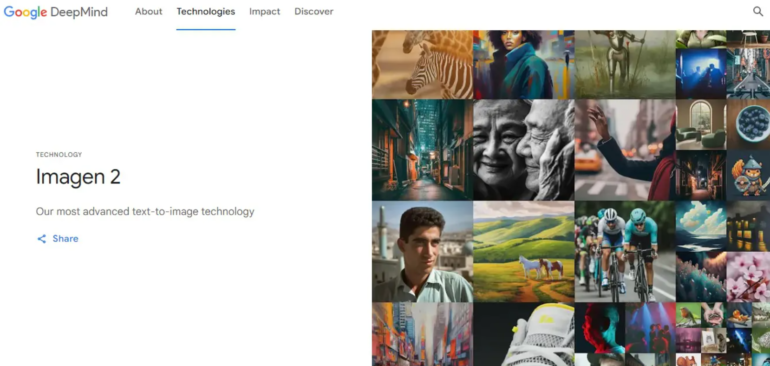
In the realm of artificial intelligence, Google has unleashed Imagen 2, the second iteration of its image generation model, armed with the prowess to craft and enhance images based on textual prompts. Targeted initially at Google Cloud users within the Vertex AI domain who’ve secured access approval, Imagen 2 has a certain veil of mystery surrounding its training data sources, with no provision for contributors to opt-out or seek compensation.
Deemed as an upgraded sibling, Imagen 2 was discreetly unveiled during Google’s I/O conference back in May. Powered by technology hailing from Google’s AI powerhouse, DeepMind, Imagen 2 boasts a “significant” advancement in image quality, although the company has curiously refrained from sharing image samples until now. This new iteration introduces an array of capabilities, notably the proficiency to render text and logos.
Google Cloud CEO, Thomas Kurian, elaborates, “If you want to create images with a text overlay — for example, advertising — you can do that.” The addition of text and logo generation aligns Imagen 2 with other prominent image-generating models like OpenAI’s DALL-E 3 and Amazon’s Titan Image Generator. However, Imagen 2 distinguishes itself by accommodating text rendering in various languages, including Chinese, Hindi, Japanese, Korean, Portuguese, English, and Spanish, with more linguistic capabilities slated for a 2024 release. Furthermore, it possesses the unique ability to overlay logos onto existing images.
Vishy Tirumalasetty, head of generative media products at Google, elucidates Imagen 2’s capabilities: “Imagen 2 can generate emblems, lettermarks, and abstract logos and has the ability to overlay these logos onto products, clothing, business cards, and other surfaces.” Thanks to innovative training and modeling techniques, Imagen 2 exhibits an improved aptitude to comprehend descriptive, long-form prompts and offers detailed responses to queries regarding elements within an image. These techniques also bolster its multilingual competency, enabling translation of prompts from one language into another.
Imagen 2 incorporates SynthID, a technology devised by DeepMind, to embed imperceptible watermarks within the images it generates. Detecting these watermarks necessitates a proprietary Google tool that is inaccessible to third parties. This measure is introduced amid concerns over the proliferation of AI-generated disinformation online.
However, Google has opted to remain tight-lipped regarding the training data employed for Imagen 2, a strategy departure from the previous iteration, which openly disclosed its utilization of the LAION dataset, which is known to contain sensitive content. The legality of training AI models on publicly available, and potentially copyrighted, data remains a contentious issue.
In contrast to some AI image generator developers who offer opt-out mechanisms and compensation schemes for contributors, Google and its counterparts like Amazon do not provide such options. Instead, Google offers an indemnification policy safeguarding eligible Vertex AI customers from copyright claims related to both training data and Imagen 2 outputs.
One persistent concern in the realm of generative AI is “regurgitation,” wherein the model reproduces training examples verbatim. This phenomenon has raised eyebrows, particularly among corporate users and developers. Addressing these anxieties, Google has extended its indemnification policy to encompass Imagen outputs, aiming to alleviate worries surrounding intellectual property.
Conclusion:
Google’s Imagen 2 represents a significant leap in AI image generation, addressing market demands for enhanced quality and multilingual capabilities. However, the secrecy surrounding training data and lingering intellectual property concerns underscore the evolving legal and ethical landscape in the AI market. Content creators may continue to seek transparency and compensation in an ever-evolving industry.