
TL;DR:
- Google’s Robotics team introduces PaLM-E, combining PaLM and Vision Transformer (ViT) models for robot control.
- PaLM-E efficiently handles multimodal input data from robotic sensors, generating precise text commands for robot actuators.
- Outperforms other models on the OK-VQA benchmark and demonstrates exceptional performance on various robotics tasks.
- PaLM-E addresses the challenge of incorporating multimodal sensor data into a large language model (LLM) through specialized encoders.
- The model enables high-level instructions, answer generation, and unifying tasks across vision, language, and robotics domains.
- Google’s open-source approach supports previous LLM systems for robot control, fostering community collaboration.
- PaLM-E integrates robot sensor data into textual inputs, enabling seamless interaction with image-based questions.
- Evaluation showcases PaLM-E’s ability to control simulated and real-world robots, excelling in complex tasks.
- Discussions highlight the scalability of performance with parameters and training set size.
- PaLM-E’s impact on the market paves the way for more capable robots and broader applications in multimodal learning.
Main AI News:
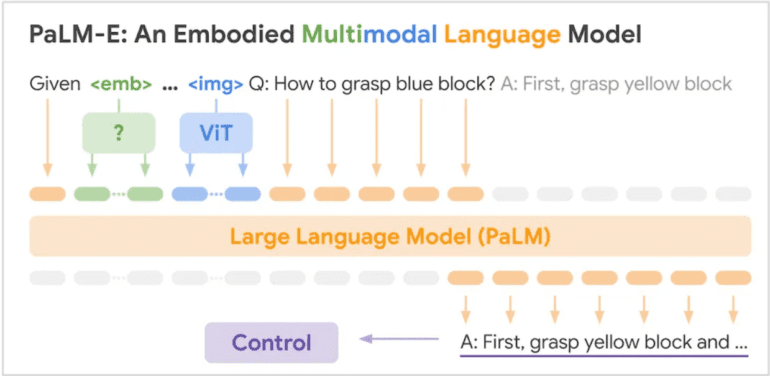
In a groundbreaking development, Google’s Robotics team has introduced PaLM-E, an innovative fusion of their PaLM and Vision Transformer (ViT) models, specially crafted for advanced robot control. PaLM-E exhibits exceptional prowess in processing multimodal input data from robotic sensors and generating precise text commands to govern the robot’s actuators. Notably, PaLM-E surpasses existing models on the OK-VQA benchmark and demonstrates remarkable performance across various robotics tasks.
The advent of PaLM-E effectively tackles the challenge of grounding or incorporating a large language model (LLM) by seamlessly integrating multimodal sensor data into the LLM’s inputs. Leveraging sophisticated encoders, the inputs undergo projection into the same embedding space utilized by the LLM for language input tokens. Consequently, PaLM-E produces articulate multimodal sentences, blending textual information with other relevant data. This groundbreaking approach empowers PaLM-E to deliver textual outputs, ranging from insightful answers to input questions to high-level directives that guide robots. Google states:
“PaLM-E represents an unprecedented leap in the training of versatile models, enabling them to concurrently address vision, language, and robotics domains. Furthermore, PaLM-E not only facilitates the development of more capable robots that capitalize on diverse data sources but also paves the way for broader applications in multimodal learning, effectively unifying tasks that were previously perceived as distinct.”
Google’s robotics researchers have consistently demonstrated their commitment to the open-source community by releasing various LLM systems tailored for robot control. In 2022, InfoQ extensively covered two notable systems: SayCan, which utilizes an LLM to generate high-level action plans, and Code-as-Policies, which employs an LLM to produce low-level robot control code.
At the core of PaLM-E lies a meticulously pre-trained PaLM language model. Through a seamless integration process, robot sensor data becomes an integral part of the textual input. For instance, the model adeptly handles input questions such as “What transpired between <img_1> and <img_2>?” with “img_1” and “img_2” denoting images encoded by a ViT and mapped to the same embedding space as the text input tokens. Consequently, the model generates accurate answers to such queries. Google has developed dedicated encoders for multiple input modalities, including robot state vectors encompassing 3D pose information, 3D scene representations, and entity references for objects within the robot’s environment.
To validate the capabilities of PaLM-E, the researchers meticulously evaluated its performance by employing it to control both simulated and real-world robots across a spectrum of complex tasks. These tasks encompassed object grasping and stacking, pushing objects in a table-top environment, and manipulation by a mobile robot in a dynamic kitchen setting. Impressively, PaLM-E excelled in constructing “long-horizon” plans for the robots, showcasing its capacity to generalize to tasks involving previously unseen objects during table-top pushing. Moreover, the model exhibited unwavering resilience in the kitchen environment, successfully completing long-horizon tasks even in the face of adversarial disturbances.
The introduction of PaLM-E sparked vibrant discussions among users on the Hacker News platform. One user expressed curiosity about the scalability of the model’s performance concerning the number of parameters. In response, another user elaborated:
“While the performance does exhibit scaling in proportion to the parameters, it does not follow a linear trajectory. Google’s work on their Chinchilla LLM discovered that performance also escalates alongside the size of the training set. They have diligently studied and defined the optimal training scale for models of varying sizes, ensuring optimal utilization of available resources. Therefore, even in the absence of superior model architectures, which we are likely to witness, increasing the size of models, training corpus, and budget will undoubtedly yield increasingly proficient models.”
The official PaLM-E website provides an array of captivating demo videos, vividly showcasing the extraordinary capabilities of robots when directed by this transformative model.
Conclusion:
The introduction of PaLM-E signifies a significant advancement in the fusion of vision and language AI for enhanced robot control. Its ability to seamlessly integrate multimodal sensor data and generate precise text commands opens up new possibilities for building more capable robots. Furthermore, the potential to unify tasks across vision, language, and robotics domains expands the scope of applications in multimodal learning. With PaLM-E, Google’s Robotics team not only pushes the boundaries of model capabilities but also provides a key enabler for advancements in the broader market, unlocking opportunities for innovation and increased performance in the robotics industry.