
TL;DR:
- Introducing GPTCache: A semantic cache for LLM answers.
- Reduces LLM query latency by caching responses for faster retrieval.
- Modular architecture allows tailored caching solutions.
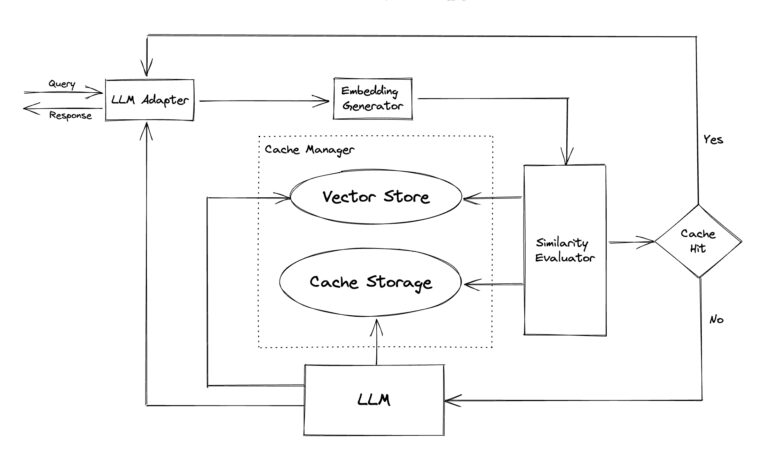
- LLM Adapter standardizes APIs for seamless transitions between models.
- Embedding Generator creates embeddings for similarity searches.
- Cache Storage supports various database management systems.
- Vector Store identifies similar requests using embeddings.
- Cache Manager handles eviction policies for efficient data management.
- Similarity Evaluator enables a unified interface for similarity algorithms.
- Enhanced responsiveness, cost savings, and increased scalability with GPTCache.
Main AI News:
In the ever-evolving landscape of language models, the ChatGPT and other large language models (LLMs) have emerged as powerful tools, empowering developers to create a wide array of innovative applications. However, as these applications gain popularity and experience a surge in traffic, the costs associated with LLM API calls can become a significant concern. Moreover, processing numerous queries may lead to lengthy wait periods for LLM services.
Enter GPTCache, a groundbreaking project that addresses these challenges by introducing a semantic cache tailored to store LLM answers. This open-source program is designed to accelerate LLMs by efficiently caching their output answers. When a response has been previously requested and is already stored in the cache, it dramatically reduces the time needed to retrieve it.
GPTCache offers flexibility and simplicity, making it an ideal solution for various applications. Notably, it seamlessly integrates with a plethora of language learning machines, including OpenAI’s ChatGPT.
The core functionality of GPTCache lies in its ability to cache the final replies from LLMs. The cache acts as a memory buffer that allows for rapid retrieval of recently accessed information. Whenever a new request is made to the LLM, GPTCache first checks if the desired response is already present in the cache. If it finds a match, the response is promptly returned. If not, the LLM generates the response and adds it to the cache for future use.
What sets GPTCache apart is its modular architecture, which enables the implementation of custom semantic caching solutions. Users can fine-tune their experience with each module by selecting from various settings.
The LLM Adapter plays a crucial role in unifying APIs and request protocols used by different LLM models, standardizing them on the OpenAI API. This not only simplifies testing and experimentation but also facilitates smooth transitions between LLM models without requiring code rewrites or learning new APIs.
The Embedding Generator is responsible for creating embeddings using the requested model to conduct similarity searches. Supported models include ONNX using the GPTCache/paraphrase-albert-onnx model, the Hugging Face embedding API, the Cohere embedding API, the fastText embedding API, and the SentenceTransformers embedding API.
In the Cache Storage module, responses from LLMs like ChatGPT are retained until they can be efficiently retrieved. When determining the semantic similarity between two entities, GPTCache fetches cached replies and sends them back to the requesting party. Remarkably, GPTCache is compatible with a wide range of database management systems, allowing users to select the one that best suits their performance, scalability, and cost requirements.
The Vector Store in GPTCache includes a module that utilizes embeddings derived from the original request to identify the K most similar requests. This feature is instrumental in determining the similarity between two requests. GPTCache supports multiple vector stores, such as Milvus, Zilliz Cloud, and FAISS, providing users with diverse options that can significantly impact similarity search performance. With its adaptability to different vector stores, GPTCache caters to a wider variety of use cases.
To manage eviction policies for the Cache Storage and Vector Store components, GPTCache employs the Cache Manager. When the cache reaches its capacity, a replacement policy decides which old data should be removed to make room for new data.
The Similarity Evaluator combines information from both the Cache Storage and Vector Store sections of GPTCache. It compares the input request to requests in the Vector Store using various approaches. Whether a request is served from the cache depends on the degree of similarity. GPTCache offers a unified interface for different similarity algorithms and a library of available implementations, making it adaptable to a broad range of use cases and user requirements.
Features and Benefits:
- Enhanced responsiveness and speed: GPTCache reduces LLM query latency, leading to a more efficient user experience.
- Cost savings: By limiting the number of API calls, GPTCache helps cut down on the cost of LLM services, thanks to token- and request-based pricing structures.
- Increased scalability: GPTCache offloads work from the LLM service, ensuring peak efficiency even as the number of requests grows.
- Cost-effective LLM application development: By caching data generated by or mock-ups in LLM, GPTCache enables app testing without excessive API requests to the LLM service.
GPTCache serves as a powerful ally, compatible with various applications, LLM (ChatGPT), cache stores (SQLite, PostgreSQL, MySQL, MariaDB, SQL Server, or Oracle), and vector stores (FAISS, Milvus, Ziliz Cloud). The ultimate goal of the GPTCache project is to optimize the use of language models in GPT-based applications by leveraging previously generated replies, thereby minimizing unnecessary redundant computations.
Conclusion:
GPTCache’s introduction into the market signifies a transformative step towards improving the efficiency and cost-effectiveness of applications utilizing large language models. With its ability to reduce query latency, provide cost savings, and handle increased scalability, businesses can expect enhanced performance and cost optimization. GPTCache’s modular design also allows for tailored solutions, making it an ideal choice for a wide range of industries and use cases. As language models continue to play a pivotal role in various applications, GPTCache offers a competitive advantage by optimizing the use of language models, setting a new standard in the market for semantic caching solutions.