
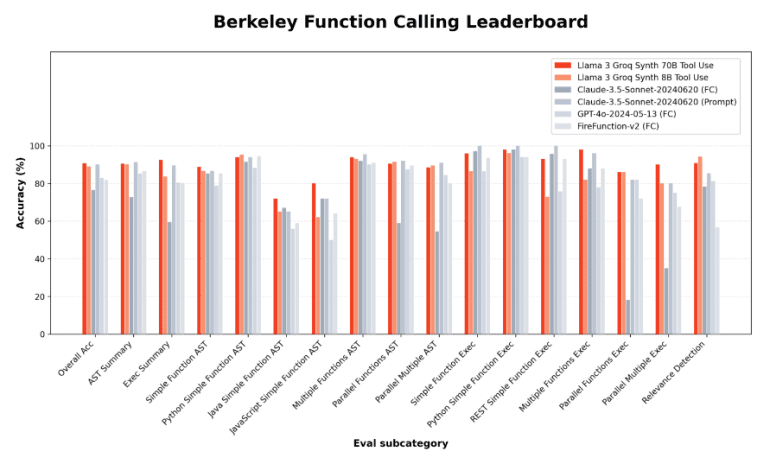
- Groq introduces Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use models, achieving top positions on Berkeley Function Calling Leaderboard.
- Llama-3-Groq-70B-Tool-Use achieves 90.76% accuracy, setting a new benchmark in function calling capabilities.
- Llama-3-Groq-8B-Tool-Use secures third place with 89.06% accuracy.
- Models are open-source, available on GroqCloud Developer Hub and Hugging Face under permissive licenses.
- Ethically trained using generated data, ensuring high performance and minimal overfitting.
- Recommended for hybrid use with general-purpose language models, optimizing performance based on query type.
- Preview access available via Groq API to encourage development and innovation.
Main AI News:
Groq has introduced two groundbreaking open-source models designed to revolutionize tool use capabilities: Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use. Developed in collaboration with Glaive, these models represent a significant leap forward in AI functionality.
The Llama-3-Groq-70B-Tool-Use model has emerged as the top-performing contender on the Berkeley Function Calling Leaderboard (BFCL), surpassing both open-source and proprietary models with an outstanding 90.76% accuracy rate. Similarly, the Llama-3-Groq-8B-Tool-Use model has demonstrated impressive performance, achieving an 89.06% accuracy and securing the third position on the BFCL. Both models are now accessible on the GroqCloud Developer Hub and Hugging Face, under a permissive style license akin to the original Llama-3 models.
These models underwent rigorous training, combining full fine-tuning and Direct Preference Optimization (DPO) methodologies. Notably, the training process relied exclusively on ethically generated data, ensuring high performance while adhering to stringent ethical standards in AI development. Rigorous contamination analysis using the LMSYS method revealed minimal overfitting, with contamination rates of just 5.6% for SFT data and 1.3% for DPO data.
Beyond their specialized tool use capabilities, the Llama-3 Groq Tool Use models are recommended for hybrid deployment alongside general-purpose language models. By employing a sophisticated routing system, these models dynamically assess user queries to select the most appropriate model for each task. For tasks involving function calling, API interactions, or structured data manipulation, the Llama-3 Groq Tool Use models excel. Meanwhile, for general inquiries or open-ended conversations, the unmodified Llama-3 70B model remains ideal. This strategic approach optimizes AI system performance by matching queries with the most suitable model.
Preview access to Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use is now available via the Groq API, with model IDs llama3-groq-70b-8192-tool-use-preview and llama3-groq-8b-8192-tool-use-preview, respectively. Groq invites developers to explore and innovate with these models through the GroqCloud Developer Hub, paving the way for future advancements in AI tool use.
Conclusion:
Groq’s release of the Llama-3-Groq-70B and Llama-3-Groq-8B models marks a significant advancement in AI tool use capabilities. Achieving top positions on the Berkeley Function Calling Leaderboard with impressive accuracy rates demonstrates their potential to enhance efficiency and performance in AI-driven applications. The models’ availability as open-source solutions with ethical training methodologies further solidifies their appeal, offering developers accessible tools to innovate and optimize AI functionalities.