
- H2O.ai introduces H2O-Danube3 series for efficient natural language processing (NLP).
- Models, H2O-Danube3-4B and H2O-Danube3-500M, trained on 6 trillion and 4 trillion tokens respectively.
- Designed for consumer hardware and edge devices, optimizing offline capabilities.
- Utilizes decoder-only architecture inspired by Llama model, enhancing computational efficiency.
- Achieves strong performance in knowledge-based tasks, demonstrating versatility for various applications.
Main AI News:
The evolution of natural language processing (NLP) continues to accelerate, particularly with the rise of small, high-performance language models. These models, optimized for consumer hardware and edge devices, offer robust offline capabilities and excel in specialized tasks like sequence classification and question answering. They represent a significant advancement over larger models like BERT and GPT-3, which are resource-intensive and often impractical for widespread deployment on consumer-grade devices.
Developing efficient language models that maintain high performance while conserving resources remains a critical challenge in NLP. Large-scale models such as BERT and GPT-3, while powerful, require substantial computational power and memory. This limitation spurred the development of smaller, more efficient alternatives capable of delivering comparable performance without the hefty resource demands.
Enter H2O.ai’s H2O-Danube3 series, designed to address these challenges head-on. The series features two main models: H2O-Danube3-4B and H2O-Danube3-500M. The H2O-Danube3-4B model, trained on 6 trillion tokens, and the H2O-Danube3-500M model, trained on 4 trillion tokens, are meticulously fine-tuned for various applications. These models aim to democratize access to advanced NLP capabilities by enabling deployment on modern smartphones and other devices with limited computational resources.
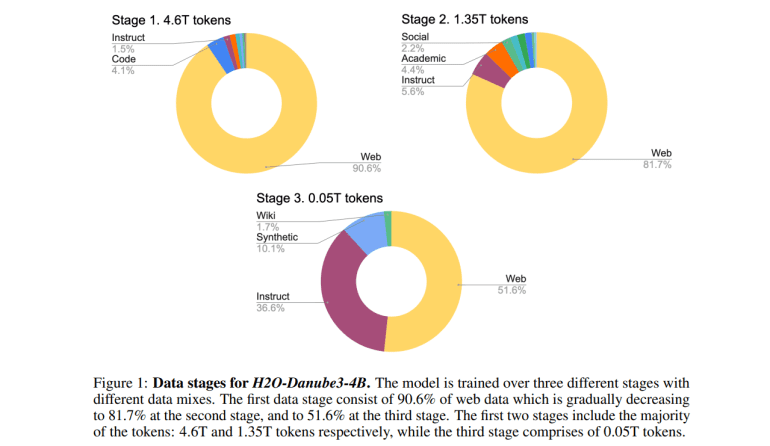
Inspired by the decoder-only architecture of the Llama model, the H2O-Danube3 models undergo a rigorous training process across three stages. This approach enhances model quality by progressively refining data mixes, prioritizing higher-quality datasets such as instruct data, Wikipedia entries, academic texts, and synthetic texts. The result is optimized parameter and compute efficiency, ensuring strong performance even on devices with constrained computational capabilities.
Key benchmarks underscore the effectiveness of the H2O-Danube3 models. The H2O-Danube3-4B model achieves notable accuracy, particularly excelling in knowledge-based tasks with a remarkable 50.14% accuracy on the GSM8K benchmark for mathematical reasoning. Similarly, the H2O-Danube3-500M model demonstrates robust performance, outperforming comparable models across eight out of twelve academic benchmarks. These results highlight the models’ versatility and efficiency, making them well-suited for diverse applications ranging from chatbots to on-device NLP solutions.
Conclusion:
The launch of H2O-Danube3 models marks a significant step forward in NLP accessibility, offering powerful capabilities optimized for consumer-grade devices. With their efficient design and strong performance across benchmarks, these models are poised to expand the application of advanced NLP technologies in consumer electronics, promising broader integration and enhanced user experiences.