
TL;DR:
- MusicMaven pioneers advanced diffusion models for refining text-to-music conversion.
- Challenges in modifying generated music without complete overhauls persist in the field.
- HarmonyNet integrates autoregressive and diffusion-based models for optimized quality and efficiency.
- Solutions like DirectSound and SynthWizard enable nuanced editing without altering underlying models.
- MusicMaven utilizes AudioSync, a framework based on variational autoencoders, for refining music based on textual inputs.
- Extensive validation experiments showcase MusicMaven’s superiority in timbre and style transfer tasks.
- Comparative assessments against benchmarks like AudioSync 2 and SymphoGen demonstrate MusicMaven’s substantial advancements.
- Datasets such as SoundScape and HarmoniX play a crucial role in highlighting MusicMaven’s refinement capabilities.
Main AI News:
In the realm of music creation, the fusion of artistic ingenuity with technological innovation has always captivated enthusiasts, culminating in compositions that evoke profound emotional resonance. Central to this process is the translation of textual descriptions into music, a domain that has witnessed considerable advancement. Yet, a pivotal challenge persists: the ability to refine or modify generated music without necessitating a complete overhaul. This intricate task demands precise adjustments to various musical attributes, such as instrument sounds or overall mood, while preserving the foundational structure.
Within the landscape of music generation models, two predominant categories emerge: autoregressive (AR) and diffusion-based models. AR models excel in producing lengthy, high-fidelity audio but at the expense of prolonged inference times, whereas diffusion models demonstrate prowess in parallel decoding despite grappling with generating extended sequences. Innovatively bridging these approaches, the cutting-edge HarmonyNet model integrates the strengths of both, optimizing both quality and efficiency. Concurrently, solutions like DirectSound and SynthWizard offer nuanced editing capabilities, empowering users to manipulate compositions seamlessly without necessitating alterations to the underlying model architecture or interface.
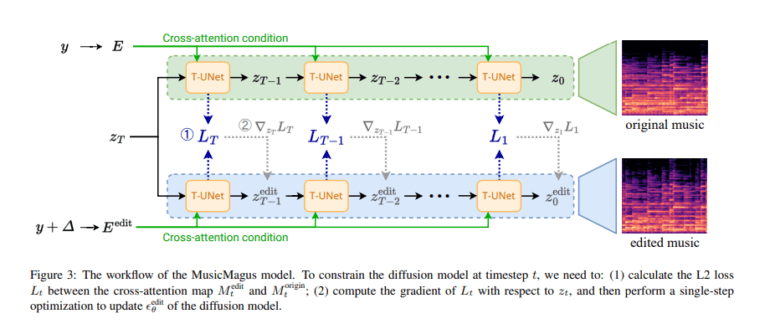
MusicMaven distinguishes itself through its unparalleled capacity to refine and polish musical compositions, employing sophisticated methodologies and leveraging diverse datasets innovatively. At its core lies the AudioSync model, a pioneering framework that harnesses variational autoencoders (VAEs) to compress music audio spectrograms into a latent space. Within this space, music is dynamically generated or refined based on textual inputs, effectively bridging the gap between linguistic cues and musical expression. Notably, MusicMaven’s editing mechanism capitalizes on the latent capabilities of pre-trained diffusion-based models, a novel approach that enhances both accuracy and flexibility in music refinement.
Extensive validation experiments have underscored MusicMaven’s efficacy, encompassing critical tasks such as timbre and style transfer. Comparative assessments against established benchmarks like AudioSync 2 and SymphoGen have been conducted, employing metrics such as CLAP Similarity and Harmonic Consistency Index for objective evaluation and Subjective Quality Score (SQS) for qualitative assessment. Results unequivocally demonstrate MusicMaven’s superiority, with a remarkable increase in CLAP Similarity scores of up to 0.33 and Harmonic Consistency Index of 0.77, indicative of substantial advancements in preserving musical semantics and structural coherence. Crucially, datasets such as SoundScape and HarmoniX, utilized in these experiments, have played a pivotal role in showcasing MusicMaven’s prowess in seamlessly refining musical compositions while preserving their inherent essence.
Conclusion:
The introduction of MusicMaven and its advanced diffusion models for refining text-to-music conversion signifies a significant leap in the market. Its ability to seamlessly bridge linguistic cues with musical expression, coupled with superior performance in timbre and style transfer tasks, positions it as a frontrunner in the realm of music creation. Businesses in the music technology sector should take note of MusicMaven’s innovative approach, potentially reshaping how music is generated and refined in the future.