
TL;DR:
- HuggingFace introduces TextEnvironments, a game-changing orchestrator for machine learning models.
- TextEnvironments bridges machine learning models and Python functions for precise task-solving.
- Key components of the TextEnvironments framework include Supervised Fine-tuning (SFT), Reward Modeling (RM), and Proximal Policy Optimization (PPO).
- TRL (Transformer Reinforcement Learning) enhances transformer language models and diffusion models with reinforcement learning.
- TRL’s lightweight wrappers, like SFTTrainer and RewardTrainer, simplify fine-tuning and modification of language models.
- PPOTrainer optimizes language models efficiently using query, response, and reward triplets.
- AutoModelForCausalLMWithValueHead and AutoModelForSeq2SeqLMWithValueHead introduce transformer models with scalar outputs for reinforcement learning.
- TRL enables training GPT2 for movie reviews, full RLHF systems, and toxicity reduction in GPT-j.
- TRL’s core mechanism involves training a language model to optimize a reward signal defined by human experts or reward models.
- Proximal Policy Optimization (PPO) modifies the language model’s policy for better performance.
Main AI News:
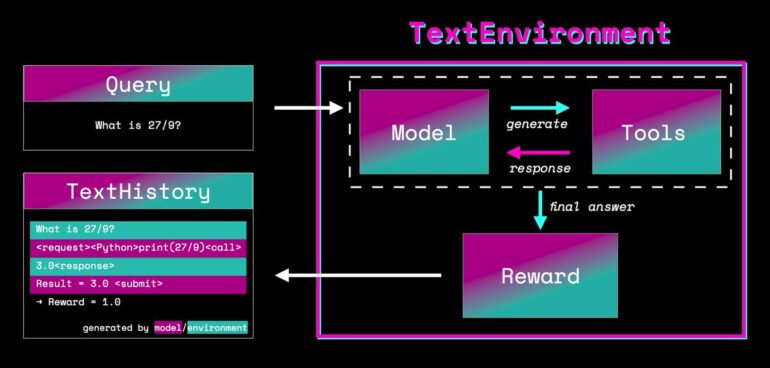
HuggingFace, a leading player in the field of natural language processing, has unveiled a groundbreaking innovation in the world of machine learning. Enter TextEnvironments, the orchestrator that bridges the gap between machine learning models and a suite of powerful Python functions. These functions serve as tools that machine learning models can leverage to tackle specific tasks with precision and efficiency.
TextEnvironments is the catalyst behind three pivotal techniques: Supervised Fine-tuning (SFT), Reward Modeling (RM), and Proximal Policy Optimization (PPO), all of which are integral components of what HuggingFace calls the Transformer Reinforcement Learning (TRL) framework. This full-stack library equips researchers with the means to train transformer language models and stable diffusion models using reinforcement learning, enhancing the capabilities of Hugging Face’s renowned Transformers collection.
One of the standout features of TRL is its ability to fine-tune language models or adapters effortlessly on custom datasets through the SFTTrainer. This lightweight and user-friendly wrapper simplifies the training process, making it accessible to researchers and practitioners alike.
Reward Modeling, a critical aspect of TRL, is made accessible through RewardTrainer. This tool allows for the precise modification of language models based on human preferences. It harnesses the power of Transformers Trainer, streamlining the process of molding language models to meet specific criteria.
For those looking to optimize language models, PPOTrainer is the answer. With just a set of triplets consisting of query, response, and reward, this tool efficiently tunes language models, making the optimization phase more accessible and manageable.
Furthermore, TextEnvironments introduces models like AutoModelForCausalLMWithValueHead and AutoModelForSeq2SeqLMWithValueHead. These transformer models incorporate an additional scalar output for each token, serving as a valuable resource in reinforcement learning as a value function.
In the realm of practical applications, TRL empowers users to train GPT2 to generate favorable movie reviews by integrating a BERT sentiment classifier. It enables the creation of a full Reinforcement Learning Human Feedback (RLHF) system using only adapters. Additionally, it works towards making GPT-j less toxic and provides examples like “stack-llama” to demonstrate its versatility.
So, how does TRL work its magic? At its core, TRL trains a transformer language model to optimize a reward signal, with human experts or reward models defining the nature of this signal. A reward model, often represented by an ML model, estimates earnings based on a given sequence of outputs. The reinforcement learning technique of choice is Proximal Policy Optimization (PPO), which modifies the language model’s policy, effectively transforming one series of inputs into another.
Using PPO, language models can be fine-tuned in three primary ways:
- Release: The linguistic model provides potential sentence starters in response to questions.
- Evaluation: Query/response pairs are evaluated using various factors, resulting in a single numeric value.
- Optimization: Log-probabilities of tokens in sequences are determined using query/response pairs. The trained model and a reference model are utilized for this purpose, and an additional reward signal is the KL divergence between the two outputs. This ensures that generated responses align closely with the reference model, and PPO fine-tunes the operational language model accordingly.
Key Features of TRL:
- TRL outperforms conventional methods in training transformer language models, offering several advantages.
- Beyond text generation, translation, and summarization, TRL empowers transformer language models to excel in a wide range of tasks.
- TRL’s efficiency surpasses that of traditional supervised learning techniques.
- Transformer language models trained with TRL exhibit enhanced resistance to noise and adversarial inputs compared to their conventionally trained counterparts.
- The introduction of TextEnvironments opens up new possibilities for developing RL-based language transformer models, fostering seamless communication and performance fine-tuning.
Conclusion:
HuggingFace’s TextEnvironments heralds a new era in machine learning, enabling businesses to leverage transformer language models for more efficient and creative natural language processing tasks. With simplified fine-tuning and optimization tools, TRL opens up diverse applications and promises improved language model performance, enhancing competitiveness in the market.