
TL;DR:
- Recent advancements in text-to-image models have generated significant interest.
- ImageReward, developed by Chinese researchers, addresses alignment issues between model training and user preferences.
- It leverages reinforcement learning from human feedback to construct a reward model (RM).
- The annotation process for RM creation is meticulous but effective.
- ImageReward outperforms other text-image scoring techniques by substantial margins.
- It aligns consistently with human preference rankings and exhibits superior discriminative capabilities.
- Reward Feedback Learning (ReFL) enhances diffusion models based on ImageReward scores.
Main AI News:
In the realm of artificial intelligence, recent years have witnessed remarkable strides in the development of text-to-image generative models. Auto-regressive and diffusion-based techniques have emerged as potent tools, capable of crafting visually captivating and semantically meaningful representations across a myriad of subjects, all in response to textual prompts. The allure of these models has stirred widespread intrigue, with many envisioning their potential applications. Yet, even as these models ascend to new heights, the road ahead is fraught with challenges.
One of the central hurdles lies in the dissonance between the distribution of pre-training data and the actual user-prompt distributions. This misalignment poses a formidable obstacle to tailoring these models to human preferences. The ramifications of this disconnect manifest in various issues that plague the resulting visual outputs, including but not limited to:
- Text-Image Alignment Errors: These encompass failures to accurately depict all the attributes, features, and connections articulated in textual prompts.
- The Body Problem: Instances where the generated images depict contorted, missing, duplicated, or anomalous human or animal body parts.
- Human Aesthetic Divergence: Departures from the prevailing aesthetic sensibilities cherished by humans.
- Toxicity and Biases: The inadvertent inclusion of offensive, violent, sexual, discriminatory, unlawful, or disturbing content.
Overcoming these pervasive challenges necessitates more than just fine-tuning model architectures and augmenting pre-training datasets. Enter ImageReward, a groundbreaking solution that promises to recalibrate the landscape of text-to-image generative models.
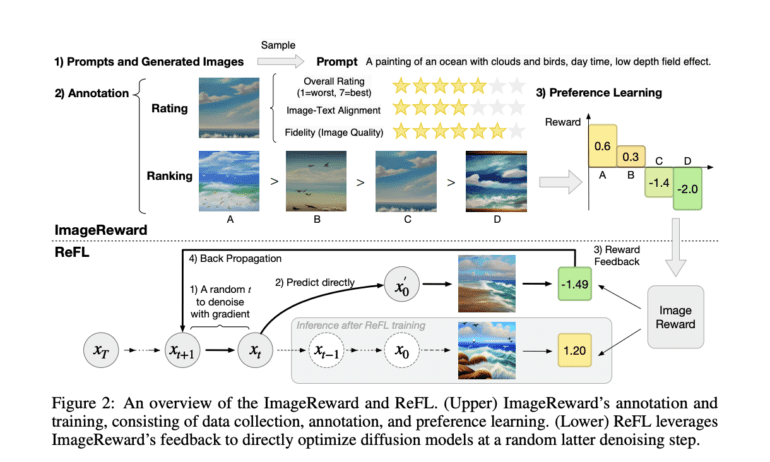
ImageReward is a result of meticulous research and development efforts undertaken by scholars from Tsinghua University and Beijing University of Posts and Telecommunications. It marks a significant milestone in addressing the issues faced by generative models. This innovative approach hinges on reinforcement learning from human feedback (RLHF) within the realm of natural language processing (NLP). At its core, ImageReward relies on the construction of a reward model (RM) through a colossal dataset of expert-annotated comparisons of model outputs. These comparisons capture the nuanced intricacies of human preference.
While undeniably effective, the annotation process is no small feat. It entails months of painstaking work, encompassing the definition of precise labeling criteria, the recruitment and training of experts, the validation of responses, and the eventual creation of the reward model.
ImageReward is meticulously trained and evaluated using a dataset comprising 137,000 pairs of expert comparisons, rooted in actual user prompts and corresponding model outputs. The researchers go above and beyond by introducing a systematic pipeline for text-to-image human preference annotation. This pipeline is designed to identify and surmount the challenges inherent in this process, laying the groundwork for quantitative evaluation, annotator training, efficiency enhancement, and quality assurance. It serves as the training bedrock for the ImageReward model.
The results are nothing short of remarkable. ImageReward surpasses other text-image scoring techniques such as CLIP (by 38.6%), Aesthetic (by 39.6%), and BLIP (by 31.6%) in its ability to decipher human preference within text-to-image synthesis. Furthermore, it demonstrates a substantial reduction in the aforementioned problems, offering profound insights into the integration of human desires into generative models.
The potential of ImageReward extends far beyond mere evaluation. It consistently aligns with human preference rankings and boasts superior discriminative capabilities across models and samples when compared to FID and CLIP scores, especially on prompts sourced from actual users and the MS-COCO 2014 dataset.
For those seeking to fine-tune diffusion models with a focus on human preference scores, the researchers propose the innovative concept of Reward Feedback Learning (ReFL). Given that diffusion models do not provide probability estimates for their generations, ImageReward’s unique ability to identify quality allows for direct feedback learning on these models. Extensive automatic and manual evaluations validate ReFL’s superiority over alternative methods, including data augmentation and loss reweighing.
Conclusion:
ImageReward stands as a testament to the ingenuity of researchers in the field of AI. It not only bridges the chasm between textual prompts and generated images but also represents a pivotal step toward harnessing the true potential of text-to-image generative models. As the world of AI continues to evolve, ImageReward is poised to play a pivotal role in shaping the future of human-AI collaboration, where preference and quality converge in remarkable harmony.